
Summary of HDR contents#
Some personal context#
When I was six years old and starting to learn to play the piano, I had fun guessing the notes my tutor was playing while I was turning my back. This was a pleasant game as I discovered that I could hear, litteraly, the label of the pitch class of individual notes as they were played. I thought everyone else could also hear them and, therefore, transcribe music easily. It was only a few years later, when joining my first music school, that I discovered I was mistaken and that music transcription is actually hard. For everyone, in fact, as even with perfect pitch, transcribing polyphonic instruments requires pattern matching with template harmonies, chords and timbre stored in the listener’s memory, and therefore requires extensive training.
As I grew older, I began to enjoy the broader concepts of sound and music processing, the Fourier transform, and their connections to how humans perceive sound, as well as the symbolic and theoretical description of music. It was with great interest that I realized, by the end of my PhD thesis, that many questions in the field of music information retrieval, which encompasses most of these concepts, could be addressed using a concept I had been working on: Low-Rank Approximations (LRA) of matrices and tensors. In particular, the design of regularizations and constraints was key to achieving reasonable performance, and I felt that, with my skill set, I could improve on the existing state of the art in that domain, particularly in automatic music transcription.
It turns out that LRA, which are the main topic of this manuscript, are quite heavily beaten in practice by deep learning approaches when it comes to transcribing piano pieces. This anecdote shows however that LRA are ubiquitous and critical to unsupervised machine learning. While some researchers specialize in one specific application of LRA, I am rather interested in the applied mathematical side of LRA, in particular in modeling and training aspects. I am convinced that LRA-based learning algorithms, in many applications such as automatic music transcription, can still be improved in light of the new results obtained over the last decade, a very modest part of which I am responsible for. It would bring me great joy to see anyone design a state-of-the-art automatic transcription algorithm that relies heavily on LRA, combined for instance with deep learning, for rare instruments with scarce training data. I firmly believe that this objective is within reach in the coming years.
I write this “Habilitation à Diriger des Recherches” (HDR) manuscript with the hope of demonstrating that regularized LRA (rLRA) is a rich topic with many exciting open questions. I also hope that fellow researchers who are willing to read through all this content will learn about some lesser-known results, tricks, and algorithmic details that can help them in their work on rLRA.
Why regularized low-rank approximations#
LRA are workhorse methods in several unsupervised machine learning tasks such as dimensionality reduction [Golub and Van Loan, 1989, Hotelling, 1992, Tucker, 1966] and blind source separation [Harshman, 1970, Lee and Seung, 1999, Paatero, 1997]. The most prominent LRA method in machine learning is probably Principal Component Analysis (PCA), which numerically boils down to computing a Singular Value Decomposition (SVD), and is therefore efficiently computed.
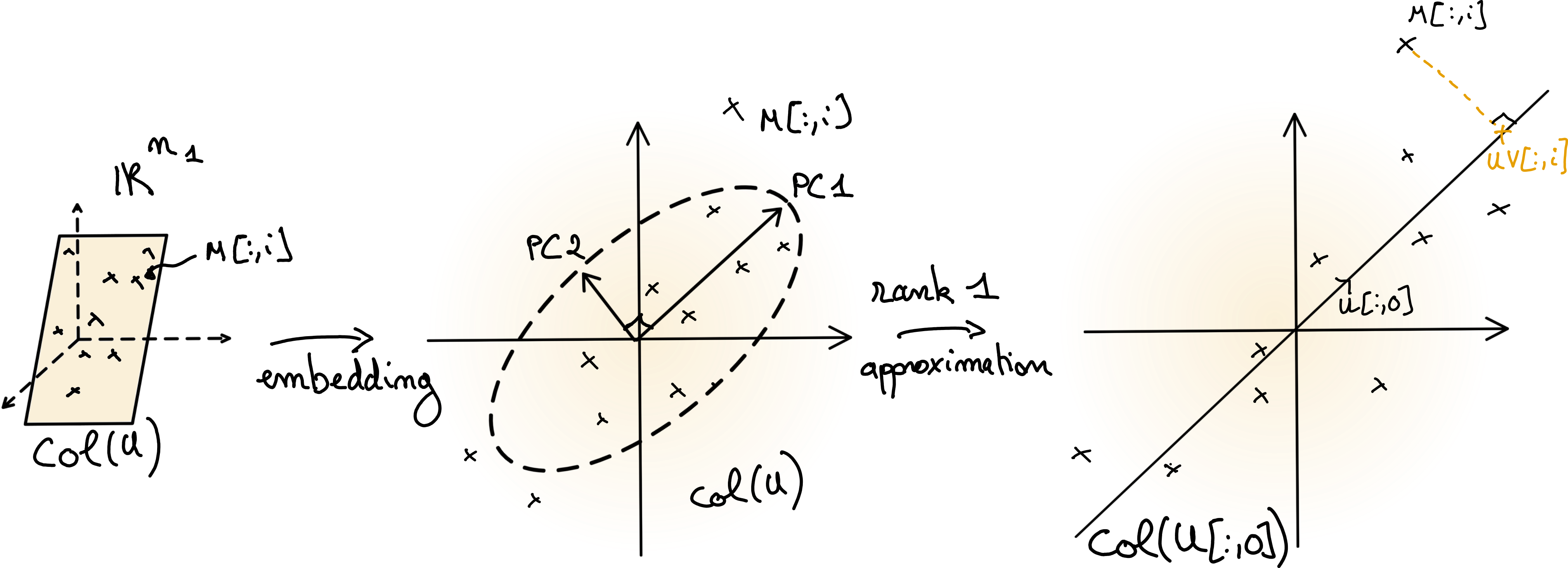
Fig. 2 Illustration of PCA. The centered data matrix \(M\) lies in a low-dimensional subspace \(col(U)\). If the orthogonal matrix \(U\) is computed from the data matrix \(M\) using SVD, then the columns of \(U\) are the principal components (scaled in the figure). An LRA is obtained by projecting the data points on a subset of the principal components; in the right plot, on the first component.#
Formally, for matrix data, a real LRA problem is an optimization problem of the form
where integer \(r\) is the rank of the approximation \(UV^T\approx Y\), with \(r\ll m,n\), and \(f\) is a cost function, typically \(f(Y, X) = \|Y-X\|_F^2\).
In unsupervised machine learning tasks, users often seek to give a physical meaning to the factor matrices \(U\) and \(V\).
In this context, there exists a true pair \((U^\ast, V^\ast)\) that the user seeks to recover, and LRA can be seen as an inverse problem. A necessary condition to correctly interpret a reconstructed pair is the uniqueness of the LRA solution. However, LRA, as defined above, is never unique, since any product \(UV\) can also be written \(UPP^{-1}V\) for an invertible matrix \(P\) of size \(r\times r\).
A widely used approach in signal processing and machine learning to restrict the set of solutions to an inverse problem is to incorporate prior information on the parameters in the form of constraints or regularizations. rLRA can be formulated as
where \(g_U\) and \(g_V\) are regularizations promoting certain properties in solutions, such as smoothness, sparsity, or nonnegativity. Depending on the choice of regularizations, the solutions may be unique.
Note
Regularizations typically apply to each factor \(U\) and \(V\) independently. Indeed, the main identifiability issue in LRA is the rotation ambiguity \(UV^T = UP\left(VP\right)^T\) for an orthogonal matrix \(P\). A regularization \(g(UV^T)\) would not discriminate between two solutions and therefore is not enough to ensure the uniqueness of rLRA solutions.
PCA is a constrained LRA model: factors are imposed to be orthogonal matrices. This allows us to obtain a model with essentially unique factors (under the mild condition that singular values must be distinct [Golub and Van Loan, 1989]), but orthogonality is often not a physically meaningful constraint. In the context of inverse problems, this means that the estimated matrices \(U\) and \(V\) may be poor approximations of the ground truth matrices \(U^\ast\) and \(V^\ast\). On the other hand, Nonnegative Matrix Factorization (NMF), obtained by setting \(g_U\) and \(g_V\) to characteristic functions of the nonnegative orthant, can be unique [Gillis, 2020] while using more realistic assumptions. In many applications, elementwise nonnegativity is a natural assumption, which makes NMF particularly suited as a source separation/pattern mining model. A typical example of NMF usage is in spectral unmixing for remote sensing, as illustrated in Fig. 3, see also Applications of rLRA: summary.
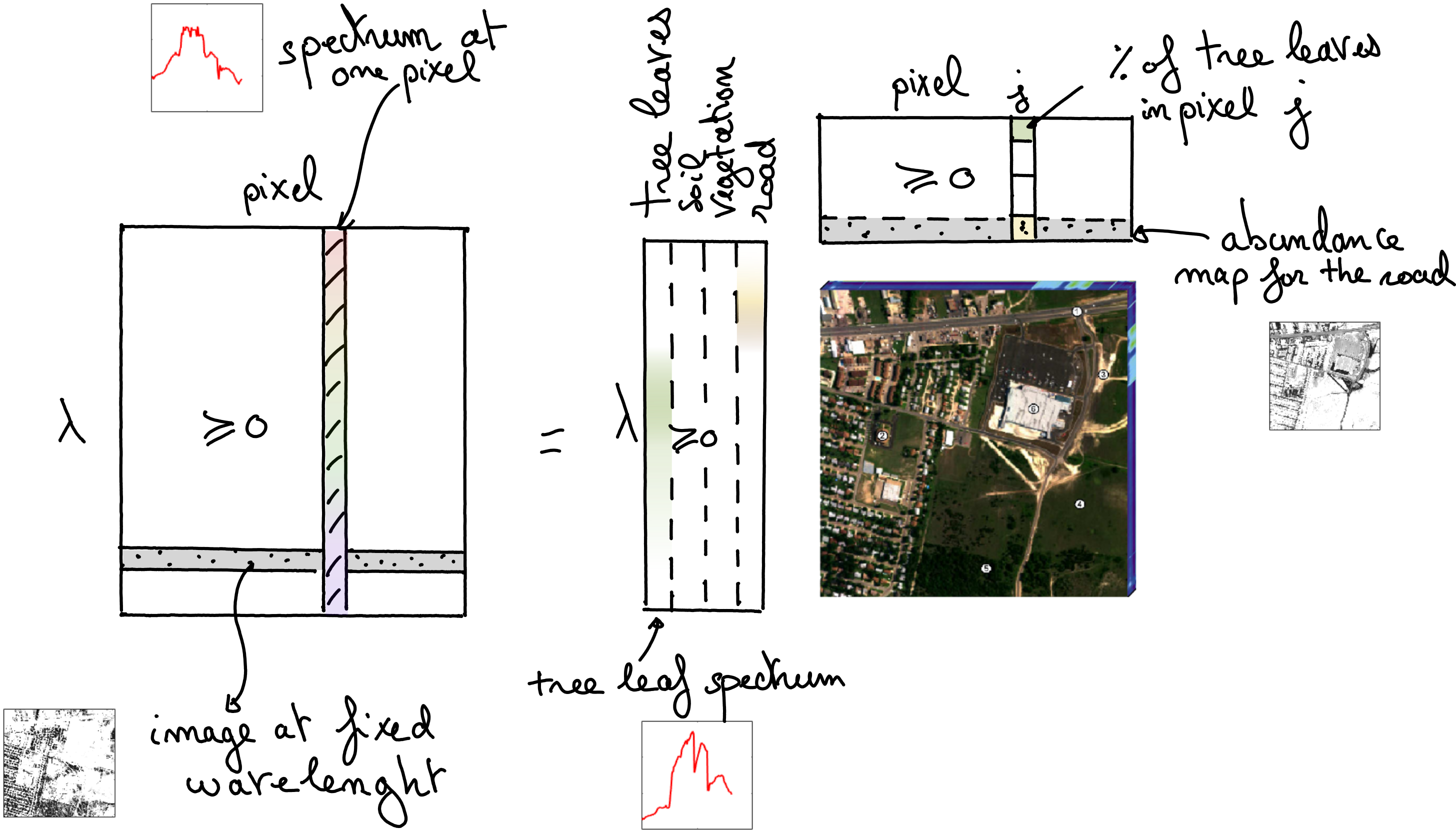
Fig. 3 NMF performs spectral unmixing on hyperspectral images, identifying essential spectra that are present in the scene, as well as their proportion in each pixel stored in abundance maps. The images are vectorized in the data matrix and the abundance maps.#
An extension of matrix LRA is tensor LRA, which applies to input data with more than two dimensions. Tensor LRA has several interesting properties, including, in the case of the Canonical Polyadic Decomposition (CPD), identifiability without the need to regularize [Kruskal, 1977]. In practice, however, regularization, and in particular nonnegativity, is often useful to improve the interpretability of the estimated parameters from tensor LRA. Section Low-rank matrix and tensor models describes known results on matrix and tensor LRA in more detail.
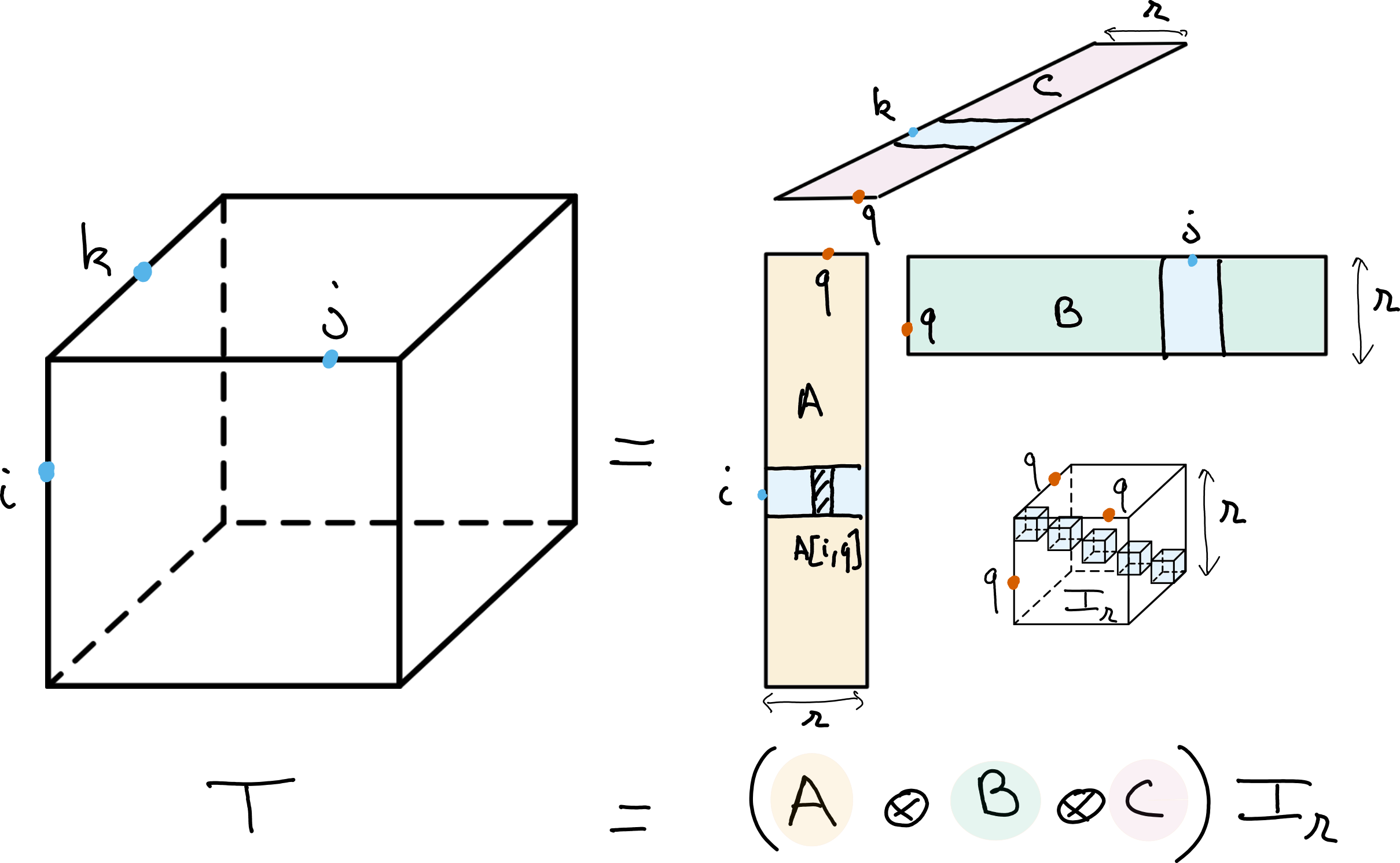
Fig. 4 CPD of rank \(r\) of a data tensor \(T\). The CPD can be viewed as a multilinear diagonalization technique, with bases \(A\), \(B\) and \(C\) respectively spanning the columns, rows and fibers of the tensor.#
Once an LRA model has been chosen for a particular application, as in most machine learning problems, the model parameters need to be estimated so that the model fits the data. Optimization problems encountered in rLRA problems are often continuous but nonsmooth, for instance, due to the nonnegativity constraint, and nonconvex due to the presence of the product of variables in LRA. Convexity, however, often holds when the cost function is considered only with respect to one of the parameter matrices. Consider the Nonnegative Least Squares (NNLS) problem with Frobenius data fitting
which is essentially NMF where the matrix \(V\) is fixed. The cost with respect to \(U\) is convex, and tools from convex numerical optimization can be leveraged to compute NMF. Therefore, for the applied mathematician working on rLRA, it is important to be familiar with both nonsmooth, constrained and convex optimization and multi-block optimization often solved with Alternating Optimization (AO) strategies. The specific case of nonnegatively-constrained regressions is of critical importance to this manuscript and is covered in depth in Nonnegative regressions: NNLS and NNKL, while a summary of known results regarding AO strategies is provided in Alternating optimization.
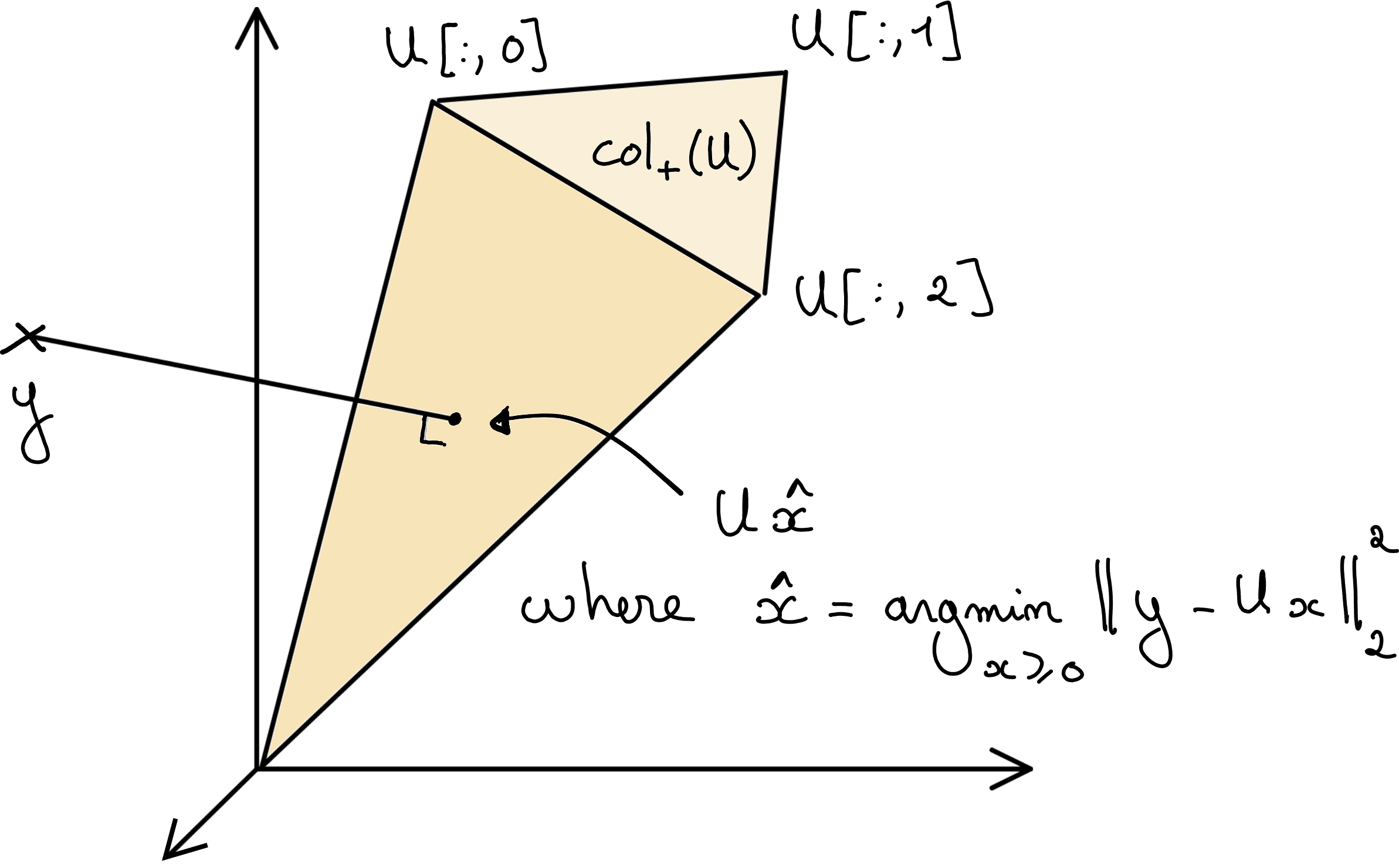
Fig. 5 Graphical representation of the NNLS problem. NNLS consists in the orthogonal projection of the data vector \(y\) on the cone \(\cp{U}\) spanned by the nonnegative linear combinations of the columns of matrix \(U\).#
There is a significant body of literature on rLRA with a myriad of applications, for instance in chemometrics [Bro, 1996], neuroscience [Cichocki, 2011], statistical inference [Anandkumar et al., 2015], spectral unmixing for remote sensing [Bioucas-Dias et al., 2012] or microscopy imaging [Hariga et al., 2024], music information retrieval [Smaragdis and Brown, 2003], telecommunications [Sidiropoulos et al., 2000], psychometry [Harshman, 1972] and more. There is no dedicated section to reviewing all these applications in this manuscript. Datasets from hyperspectral imaging and music information retrieval are used to illustrate the various contributions, and my contributions to these applications are detailed in a separate chapter.
Contributions to regularized low-rank approximations#
Since the start of my PhD thesis in 2013, I have focused my research on rLRA models as tools for extracting meaningful information out of matrices and tensors, using regularizations to enhance interpretability. These regularizations often include nonnegativity, which has become my specialty. My work covers a diverse range of topics, from understanding the properties of solutions to rLRA to proposing new applications for these models. A significant portion of my work is dedicated to algorithm design for efficiently computing solutions to rLRA across various setups.
Challenges in rLRA#
Despite the large body of existing work on rLRA, its use by practitioners is often quite difficult. Indeed, there are many exciting theoretical and practical issues that remain to be dealt with:
Optimization problems stemming from fitting rLRA models are multi-block, nonconvex, and often nonsmooth. Recent advances in numerical optimization, including acceleration, majorization-minimization, generalized projection operators, and AO, can all be leveraged to improve upon the state-of-the-art. It is also unclear, in practice, which optimization algorithm to use depending on the context.
Side information is often available alongside the matrix or tensor data, which transforms the unsupervised rLRA learning problem into a semi-supervised or fully supervised problem. This information can take diverse forms: a known library of templates for the unknown sources, a downstream task with available training data, deep priors for the unknown sources such as provided by deep denoisers, or, among others, sparsity in well-known bases. Accounting for this side information in rLRA is often not straightforward, both from a modeling and from a training perspective.
Multimodality has emerged as an important topic in source separation, where the same phenomenon is observed through different sensing devices. A typical example would be acquiring brain activity through EEG and fMRI jointly. The joint processing of the acquired dataset can be performed by several coupled rLRA. The research questions on joint rLRA typically revolve around the coupling model, and the design of flexible algorithms to solve a wide range of multimodal source separation problems, in particular when the datasets have different dynamics, noise levels, and even different fields (such as floats vs count vs categorical data).
The rLRA models themselves still have elusive properties. An important example is nonnegative Tucker decomposition, for which identifiability is unclear in many cases, despite recent advances on the topic [Saha et al., 2025]. Generally, a user needs guarantees about the nature of rLRA solutions, and such theoretical guarantees are challenging to obtain, especially when the hypotheses must be verifiable in practice.
The scientific software ecosystem is a dimension often overlooked but critical in practice. Available software for tensor decomposition is largely bloated; see the survey by Psarras et. al. from 2022, which lists over 70 tensor packages scattered across the internet [Psarras et al., 2022]. However, software packages dedicated to, or capable of handling at least partially, rLRA are scarce. For tensor decompositions, many packages focus on the decomposition itself but do not use efficient large-scale contractions on CPUs or GPUs that are crucial for up-scaling [G. A. Smith and Gray, 2018, Li et al., 2015, Smith and Karypis, 2015]. Another critical issue is the actual implementation of rLRA algorithms, that requires non-trivial caching of expensive operations and speed-memory trade-offs that are research topics by themselves [Kaya and Uçar, 2016].
Improving on theory, algorithms, and applications#
My work has been dedicated to proposing (partial) solutions to these issues. I have grouped my contributions into three parts: theoretical contributions, application-oriented contributions, and algorithmic-focused contributions. However, in most of these works, all three aspects (theory, algorithms, applications) are intertwined, so this is not a strict segmentation.
The three main parts of this manuscript are
Theory of rLRA, where I summarize my contributions to the analysis of several sparse models: dictionary-based LRA, sparse nonnegative least squares. I also study the impact of scaling ambiguity on rLRA solutions, which can induce unexpected group-sparsity at the component level.
Algorithms for rLRA. My contributions concern flexible algorithms for multimodal rLRA, heuristic inertial acceleration for AO algorithms, and more recently, the design of tight surrogates for nonnegative optimization problems, including NMF in non-Euclidean settings. I have also worked on data-driven regularization for LRA, in particular on unrolling multiplicative updates for NMF. Finally, I revis a work from my PhD thesis on projected least squares to compute nonnegative LRA.
Applications of rLRA. My expertise in terms of applications of rLRA is geared towards both spectral imaging and music information retrieval, in particular automatic transcription. My interest in spectral imaging stems from the fact that LRA is intimately linked to additive mixtures, which accurately describe mixtures in spectral acquisition techniques such as fluorescence spectroscopy or hyperspectral remote sensing. Being a semi-professional pianist, composer and singer, I have a personal interest in music that drives my research in music information retrieval. Other applications, mostly related to biomedical imaging, are more punctual collaborations and are described below.
This manuscript dives quite deep into the details of the selected contributions. A general overview of my work can still be obtained by reading only the introductions of Theory of rLRA, Algorithms for rLRA, and Applications of rLRA, which contextualize and summarize the works detailed in each part.
There is no section in this manuscript dedicated to software development. Instead, simple implementations of the methods under scrutiny are provided inline, imported from tensorly, which I have co-developed since 2019, or imported from a local set of methods developed specifically for this manuscript. Software development is an important part of scientific contributions in rLRA and, more generally, in applied mathematics. In my opinion, it is important to show the exact code being run for experiments and illustrations so that readers can be more deeply convinced of the results’ exactitude.
Other works#
Several of my works are not discussed in details in this manuscript. They are often targeted toward specific applications or require dedicated mathematical tools that I want to avoid introducing here. Below is a short paragraph for each of these works.
Music segmentation#
One of the most impactful work that I chose not to detail is related to the PhD thesis of Axel Marmoret [Marmoret et al., 2020, Marmoret, 2022, Marmoret et al., 2022]. Low-dimensional models such as Tucker decomposition and auto-encoders are used to compress information from a recording of a full song [Smith and Goto, 2018]. This compression highlights the similarities and dissimilarities between bars in the song, which then helps a dedicated dynamic program solver to perform an automatic segmentation of the song. Despite the method being unsupervised (a supervised beat-tracking algorithm is still used to cut the song into bars), the results are very encouraging if the parameters of the compressed models can be chosen optimally. This choice is difficult in practice, which limits the method’s performance.
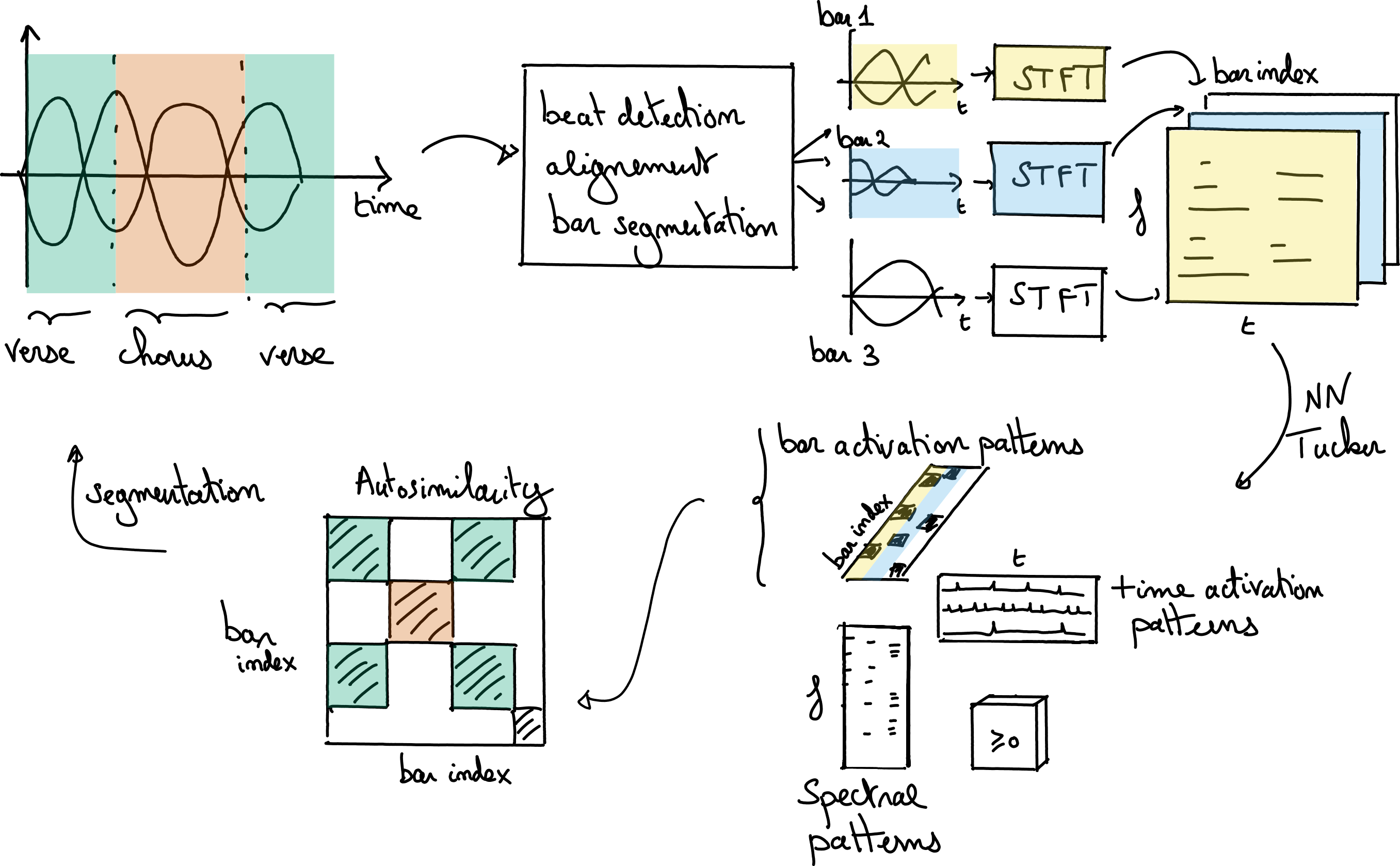
Fig. 6 Nonnegative Tucker decomposition can be used to extract meaningful patterns from a Time-Frequency-Bar tensor, obtained from an audio recording of a song by slicing the audio barwise and applying individual short-time Fourier transforms. The bar activation patterns are then used as low-dimensional features to perform automatic segmentation on an auto-similarity matrix, revealing the hidden structure of the song.#
This work was rather visible in the music information retrieval community when released. It has launched the academic career of Axel Marmoret, who is today working, among other areas, on LRA in conjunction with deep learning and their applications to music information retrieval. His PhD manuscript describes our contributions in detail.
Birkhoff-von Neumann decomposition of stochastic matrices#
The Birkhoff-von Neumann (BvN) decomposition of a stochastic matrix writes a bistochastic matrix \(M\) as a minimal number of permutation matrices \(P_i\),
where \(\alpha_i\) are nonnegative coefficients; both coefficients and permutation matrices have to be estimated from the input matrix. This long-standing NP-hard problem can be tackled by a variety of existing heuristics. In collaboration with Bora Uçar and Damien Lesens, we proposed viewing BvN as a sparse coding problem and adapting existing sparse coding solvers, such as Orthogonal Matching Pursuit (OMP), to compute solutions [Lesens et al., 2024]. The contribution is to link the selection of the best atom (here, the best permutation matrix) to several graph matching algorithms, making the selection both fast and effective. Our method is competitive with the state-of-the-art. In a follow-up work driven by Damien Lesens, we extended BvN algorithms to the symmetric case [Lesens et al., 2026]. We are the first to propose an implementable algorithm to solve symmetric BvN.
These works fall slightly outside the realm of rLRA. My role for the second contribution on symmetric BvN, in particular, was rather minor. Therefore, I chose not to discuss this work further. Damien Lesens is now pursuing a PhD co-supervised with Bora Uçar on optimization algorithms for nonnegative LRA, see the Perspectives.
Sparse separable NMF#
Separable NMF is a regularized variant of NMF with nice identifiability and algorithmic properties, see the dedicated section in Low-rank matrix and tensor models. In a joint work with Nicolas Nadisic, Arnaud Vandaele, and Nicolas Gillis, we studied a slightly more general model called sparse separable NMF, which assumes that the data points are sparse convex combinations of a few data vectors [Nadisic et al., 2021]. An algorithm is proposed ressembling OMP that identifies the components from the data directly, and compute sparse regressions for each data point using a previously proposed sparse NNLS algorithm. We show, however, that the problem is in general NP-hard, unlike separable NMF.
Optical Biopsy NMF#
A contribution closely related to Single-pixel hyperspectral image reconstruction and unmixing performs segmentation of cancerous cells from videos of the brain during surgery using separable NMF [Caredda et al., 2023], in collaboration with Bruno Montcel, Charly Carrera, and others. For this work, my contribution is to propose a robust variant of the well-known direct algorithm for rank-two exact separable NMF in the Frobenius norm. The components estimated from the rank-two NMF are then used to estimate the spatial oxygenated blood flows, which help locate the glioma.
Lever arm tensor decomposition#
In a collaboration with Raphaël Dumas and Joris Claude, we studied a set of lever arm measurements from leg muscles acquired on patients with knee injuries during walking [Claude et al., 2024]. This study revealed synergies among leg muscles. These muscle activations can be clustered to summarize the complex action of the human body during walking into a few descriptors. My contribution to this work was to help design the constrained tensor decomposition model. The data tensor is quite difficult to decompose, and running unconstrained CP decomposition yields inconsistent results across runs; using sparsity and nonnegativity priors helped reduce this variability and improve the interpretability of results. Joris Claude is now pursuing a PhD in biomechanical systems.
Perspectives#
Research objectives#
There have been at least two sources of frustration in my research work so far. First, I have always been very interested in the applied mathematics aspects of signal processing, and many of my current contributions are based on heuristics or lack a clean theoretical motivation. Second, numerical optimization is the bread and butter of rLRA, but there is a large body of literature on numerical optimization that I am still unfamiliar with. I have the impression that contributions to numerical optimization, with the practical challenges of rLRA and its applications in mind, are within reach and can be impactful. Therefore, in the coming years, my main objective is to dedicate more research time to understanding the intricacies of numerical optimization and to propose theoretically motivated algorithms both for convex and nonconvex problems.
An optimization problem that I believe is particularly interesting is the so-called NNKL problem described in Nonnegative regressions: NNLS and NNKL, namely, solving linear regressions under the Kullback-Leibler divergence (KL-divergence) loss. For an input nonnegative data vector \(y\in\mathbb{R}_+^{m}\) and a linear observation matrix \(A\in\mathbb{R}_+^{m\times n}\), NNKL can be formulated as
where \(\KL{y,z} = \sum_{i} y[i]\log(\frac{y[i]}{z[i]}) + z[i] - y[i] \) is the KL-divergence. This optimization problem is quite challenging for at least two reasons:
The cost function is not Lipschitz-smooth at zero. Lipschitz-smoothness is a key property of cost functions leveraged in most convergence proofs of first-order methods. In practice, choosing a step-size for first-order methods can be challenging without Lipschitz-smoothness.
When \(y[i]\) is significantly smaller than \(z[i]\), the loss is almost linear (the logarithmic term vanishes). This means that the cost function is not strongly convex, another important property that guarantees the practical speed of first-order methods.
# Showing plots for 1d Kullback Leibler with slider for data position
x = np.linspace(1e-5, 10, 300)
def kl_divergence(p, q):
"""Calculate the scaled KL divergence between two positive vectors."""
return np.sum(p * np.log(p / q) + q - p)
y = np.zeros_like(x)
p = 2.5 # Initial data
for i, q in enumerate(x):
y[i] = kl_divergence(p, q)
The optimization community has dedicated significant effort to proposing algorithms to solve problems such as NNKL. Multiplicative Updates (MU) is such an algorithm that works well in practice. However, few methods can solve constrained variants of NNKL. In the current state of signal processing, where data-driven methods such as plug-and-play and unrolling algorithms yield significant performance gains, there is a need for algorithms that solve such nonsmooth, non-Lipschitz-smooth, nonconvex problems. I also plan to work on improving the state-of-the-art for solving NNKL and related problems, as I believe that within the frameworks of majorization-minimization and second-order approximation, significant gains can be made. We have already started to propose better approximations of the cost, but more work is required in this direction to find faster algorithms, robust to data and parameter sparsity, that can scale to large datasets.
Finally, there is a dire need for a community-oriented optimization benchmark in rLRA. As mentioned above, the number of software libraries for performing LRA is extremely large; however, to this day, as far as I am concerned, it remains unclear which optimization method should be used in which context, and which implementation is the best on the market. I will start making efforts towards such benchmarking tools, starting with NMF. The benchmark structure has already been completed using the benchopt framework, in collaboration with Cassio Fraga-Dantas, and we are working with several authors, in particular Damien Lesens, on filling up the benchmark with algorithms and datasets.
The perspectives of my research on NNKL, and more generally Poisson-distributed problems, are further detailed in Numerical optimization for KL-based regularized inverse problems.
A related, important line of work for the future focuses on Single-Pixel Imaging (SPI). Perspectives on this topic include
A joint reconstruction and unmixing of single-pixel images with deep priors (such as plug-and-play and unrolling). This is the topic of the end of Serena Hariga’s PhD thesis.
Better algorithms for Poisson noise problems, as discussed above.
A deeper understanding of Poisson-Gaussian equivalences, and estimation under Poisson-Gaussian noise. Anna Jezierska and co-authors have already worked on this problem in the context of inverse problems [Chouzenoux et al., 2015], but I believe there could be additional discoveries to be made. In particular, known results about Poisson-Gaussian equivalences in high-count settings, although standard in the optics and statistics community [Curtis, 1975, Seifert et al., 2023], are not easily summarized or put in use in a numerical optimization context. This work could be performed in collaboration with Valentin Debarnot, recently recruited to CREATIS.
These topics are also discussed in Numerical optimization for KL-based regularized inverse problems. Other interesting topics regarding SPI are discussed in Other perspectives. A first topic of interest is the design of the acquisition operator, putting the theory of compressive sensing to the test. A second topic is the derivation of separable NMF heuristics for inverse problems. The low-rank data matrix is not observed directly, therefore one may not simply pick columns from it as traditionally done in separable NMF. Finally, a last topic of interest is Borgen plots [Neymeyr and Sawall, 2018], and more generally, algorithmic tools for studying uniqueness of solutions in inverse problems. Borgen plots show all possible solutions of NMF graphically for rank three, but their generalization to higher dimensions and ranks, as well as to other inverse problems [Munier et al., 2025, Sawall et al., 2022], remains an open problem.
About the evolution of research on rLRA#
In the long run, with the rise of deep learning and the success of end-to-end black-box modeling coupled with the increasing ease of collecting large training datasets or generating synthetic ones, one may fear that unsupervised machine learning techniques, and in particular LRA, could become obsolete. My honest answer to this observation is that there is indeed a risk that LRA models, and more generally physics-inspired models, may not be required to achieve state-of-the-art results across a wide range of applications. Looking at the current state of things, however, there are at least two reasons to hope for a future in signal processing and AI in which LRA still plays an important role.
Physics-driven AI is currently a promising research direction to “open the black box”. By using physical models, for instance, as forward operators, the performance of deep learning systems may not improve, but can be more robust to distribution shifts [Lorente Mur et al., 2022]. Unrolling optimization algorithms provides a means to guide the design of neural networks motivated by traditional optimization algorithms. Plug-and-play methods enable the use of black-box models within physics-driven iterative algorithms. Although the resulting algorithms can still work in mysterious ways.
LRA is a fundamental tool in numerical linear algebra, signal processing, and machine learning. Many researchers are already working on using LRA to improve the design or training of deep learning architectures. A famous example of this is LORA [Hu et al., 2021], but other works have considered more involved usage of LRA models in deep learning [Borsoi et al., 2025, Kossaifi et al., 2020]. Another more personal view on this matter is that rLRA can always be used as a trustworthy baseline in the future, even if more advanced models may significantly outperform it. In applications such as automatic transcription, it can be refined in multiple ways so that its performance is close to that of deep learning [Marmoret et al., 2020]. If the current generation can produce efficient and flexible software for rLRA, it is reasonable to assume that, in applications where rLRA performs well, it will be used as an unsupervised baseline for the foreseeable future. The manuscript and the codes furnished along the way are, hopefully, one small step towards this goal.