
Unrolled MU for data-driven NMF#
Reference
[Kervazo et al., 2024] C. Kervazo, A. Chetoui and J. E. Cohen, “Deep unrolling of the multiplicative updates algorithm for blind source separation, with application to spectral unmixing”, EUSIPCO 2024. hal
[Kervazo and Cohen, 2025] C. Kervazo, J. E. Cohen, “Unrolled Multiplicative Updates for Nonnegative Matrix Factorization applied to Hyperspectral Unmixing, submitted pdf
Data-driven NMF principles#
Data-driven NMF through regularization#
Low-rank approximation models such as NMF are designed to perform unsupervised learning: given a data matrix \(Y\), their goal is to compute two possibly constrained matrices \(W,H\) such that \(Y\approx WH^T\). In practical applications, as discussed in Applications of rLRA: summary, however, performing LRA is not the final goal. The estimated factor matrices are instead further processed for a downstream task. These post-processing operations include clustering of the components, thresholding activations, or performing linear regression. Often, additional side information is available on the expected outcome of this post-processing. In the language of machine learning, we could say that this additional information takes the form of training data stored in a matrix \(M\).
A simple way to make use of this additional data \(M\) is to modify the LRA cost to incorporate this data. This procedure has been named “Supervised LRA” in the literature, see [Lock and Li, 2018] and references therein. For NMF, linear regression from a matrix \(W\) to additional data \(M\) can, for instance, drive the supervision task. The “supervised” NMF problem formulation is then given by
for a regularization hyperparameters \(\lambda>0\), a data fitting term \(\mathcal{D}\) such as the squared Frobenius norm \(\|Y-WH^T\|_F^2\), and regression parameters \(\theta\) trained jointly with the NMF factors.
One could argue that this approach does not really leverage training data to train a model in the way usually understood in supervised learning. Regression parameters \(\theta\) are learnt from scratch for each pair of data matrices \((Y,M)\). Matrix \(M\) must also be known at inference time.
A modification of this supervised LRA framework can be considered, in which the parameters \(\theta\) are shared across \(p\) LRA problems. In the above example of supervised NMF with linear regression, given a collection of data matrices \(\{(Y_i,M_i)\}_{i\leq p}\), parameters \(\theta\) are trained to reconstruct matrix \(M_i\) from the jointly estimated matrix \(W_i\):
Parameters \(\theta^\ast\), trained on the training dataset consisting of pairs \((Y_i,M_i)\), could then be used at inference time when only a single matrix \(Y\) is known to estimate matrix \(M:=\theta^\ast W^{\dagger}\) after obtaining matrix \(W\) with NMF, or by solving the NMF and the regression problem
We can still go further. In the formulations of supervised LRA above, while the post-processing parameters \(\theta\) and the parameter matrices are optimized jointly and move the solution of the supervised LRA problem away from the best low-rank approximation, the model applied to \(Y\) is still a low-rank approximation. Modern-day machine learning often relies on black-box models based on neural network architectures that lack strong inductive biases, such as bilinearity and low-rankness. Therefore, it is tempting to also train the model, in some sense, to better fit the training data. Formally, we may assume that the forward model is a map \(\mathcal{M}(W,H,\theta)\) and solve the optimization problem
An immediate issue with this formulation is that it is unclear how to even define such a map \(\mathcal{M}\) while ensuring that the matrices \(W\) and \(H\) remain interpretable in practice. Another issue is that computing the minimizers using first-order methods requires computing the derivatives of \(\mathcal{M}\) with respect to both the matrix \(W\) and the parameters \(\theta\), which can be challenging and time-consuming depending on the definition of the model \(\mathcal{M}\). As far as I know, supervised LRA models in the same form as Equation (14) have not been studied in the literature. Rather, a more convenient way of designing data-driven LRA models is through the lens of bilevel optimization.
Bilevel formulation for data-driven NMF#
On top of the issues discussed above, a fundamental problem with supervised LRA as defined in Equation (14) is also the choice of hyperparameter \(\lambda\). Why should the user compromise between the quality of the forward pass of the model and the training of that model?
Bilevel formulations address the trade-off between model inference and parameter updates during training. There is, however, not a single canonical bilevel formulation for unrolling LRA. On the above example of supervised NMF, a naive formulation that separates the model computation (forward pass) and the actual training of the model (backward pass, i.e., updating model parameters \(\theta\) to reduce a training loss) writes
Such a bilevel optimization problem is not particularly interesting because the two optimization problems are essentially decoupled and can be solved sequentially. We are back to simply post-processing the estimated parameter matrices of NMF. Following data-driven or task-driven dictionary learning [Mairal et al., 2011, Sprechmann et al., 2014], the symmetry between matrices \(W\) and \(H\) may be broken. We then solve a bilevel problem of the form
Hence, the dictionary \(W\) is now trained to reduce the training loss \(\mathcal{L}\) while only the scores \(H_i\) are computed at the inner level. Updating matrix \(W\) means computing gradients through minimizers \(H_i^\ast(W)\), which is tractable analytically depending on the choice of the model, loss \(\mathcal{D}\), and in the presence of regularizations such as sparsity [Mairal et al., 2011]. It is, however, not obvious how to form these gradients for NMF.
The core idea of unrolling is to replace the inner optimization problem with a numerical algorithm that computes solutions to this problem:
where \(\mathcal{A}\) is a parametric algorithm to compute approximately a solution to NMF. Algorithm \(\mathcal{A}\) is chosen to be a fixed number of iterations of a truncated iterative algorithm. Note that the forward model / unrolled algorithm \(\mathcal{A}\) may depend on parameters \(\theta\) for greater flexibility.
One interesting property of unrolling is that even without training, the iterative algorithm that solves the problem, here NMF, typically works rather well for minimizing the supervision loss. In many problem instances, earlier contributions have addressed the problems at hand in a fully unsupervised manner. Therefore, finding a good initialization for the parameters \(\theta\) and the matrix \(W\) is often straightforward.
Unrolling the Multiplicative Updates algorithm#
Existing unrolled NMF algorithms break the symmetry between matrices \(W\) and \(H\). Therefore, they are not well-suited to make use of training data in the form of pairs \((Y_i, (W^{gt}_i,H^{gt}_i))\), where \(W^{gt}_i\) and \(H^{gt}_i\) are ground-truth factors. A typical use case is source separation in remote sensing, where spectra and abundance maps may be provided alongside hyperspectral images. It is also possible to generate a synthetic training dataset in which one can produce both ground-truth matrices \(W\) and \(H\).
We therefore propose to formulate data-driven NMF where both matrices \(W\) and \(H\) are outputs of the parametric algorithm, solving
The main design choices for the unrolled algorithm are
The (truncated) iterative algorithm \(\mathcal{A}\)
The trained parameters \(\theta\).
In a series of works with Christophe Kervazo, we proposed unrolling a workhorse algorithm for NMF, the MU algorithm; see Nonnegative regressions: NNLS and NNKL for a detailed presentation. Other algorithms could be considered, but MU poses an interesting challenge: there are no obvious trainable parameters \(\theta\) in the algorithm. For instance, the MU update for matrix \(W\) with Frobenius loss writes
Unrolling strategies typically train a stepsize or a linear operator in the log-prior (e.g., the finite difference operator). Strategies to unroll MU previously proposed by Nasser [Nasser et al., 2022] replace both matrix \(H\) and the cross product \(H^TH\) with trainable matrices. However, this strategy is not suited for an alternating procedure since the dependence on \(H\) is lost.
We proposed introducing trainable parameters that are multiplied elementwise with the updates. At iteration \(k\), the proposed Non-Adaptive Linearize MU (NALMU) is given by
where \(A^{k}_W\) and \(A^{k}_H\) are iteration-dependant trainable matrices. There are two advantages to this choice:
Setting \(A^{k}_W\) and \(A^{k}_H\) to all-one matrices recovers MU. Therefore, the unrolled algorithm is easy to initialize, and we can understand how it differs from MU numerically.
We can prove that when updating a single matrix, say \(W\) with fixed \(H\), and with shared weights \(A^{k}_W\) across all iterations, the modified updates of NALMU can be obtained by a majorization minimization strategy using Jensen inequality, see Nonnegative regressions: NNLS and NNKL, minimizing a modified cost function
where the data is compared to a masked NMF with factors \(W\ast A_W\) and \(H\). The trained parameters, therefore, act as weights emphasizing the reconstruction towards certain entries of \(W\).
Training NALMU#
The supervision loss for NALMU is defined as
where \(W_i^{k}(\theta)\) and \(H_i^{k}(\theta)\) ar the estimated factors from algorithm \(\mathcal{A}\) after \(k\leq K\) iterations. Functions \(\ell_W\) and \(\ell_H\) are user-defined loss functions for the factor matrices, typically \(\ell_2\) norms or application-specific metrics such as the Spectral Angular Distance (SAD) used in remote sensing. Parameters \(\nu_k\) control how much the estimated factor after \(k\) iterations impacts the supervision loss; for instance, if only the final output of algorithm \(\mathcal{A}\) should match the ground-truth, then \(\nu_k = 0\) for any \(k<K\). Setting nontrivial values for parameters \(\nu_k\) avoids training issues such as vanishing gradients and is a common trick in the unrolling literature and more generally in deep learning.
The initial weights \(A_W\) and \(A_H\) can be set to one to start the learning phase from the MU algorithm. The number of truncated iterations \(K\) is, in general, set rather low compared to the maximum number of iterations used in MU. Typically, we choose \(K=25\). The training algorithm can be any classic optimizer in the deep learning community with default parameters. For instance, the AdamW optimizer with a learning rate of \(10^{-5}\) for 1000 epochs.
An issue with unrolled NMF is the scaling ambiguity, which makes the training less consistent. A simple solution we propose is to normalize the columns of the data matrices \(Y_i\) when appropriate, and to normalize the initial guesses for the factors accordingly. As a rule of thumb, normalisation in regularized and unrolled LRA can be tricky and should be designed depending on the application at hand.
Toy example#
Providing a full example of unrolled NMF in this manuscript is rather challenging, as the training of NALMU typically requires large computing resources. Rather, a minimal working example is implemented below to train NNLS (i.e., NMF with a fixed factor matrix, here \(W\)) on synthetic images generated from a noisy mixture. The goal of this toy experiment is to showcase one key feature of unrolled algorithms: they often provide a good reconstruction in much fewer iterations than the baseline algorithm.
import torch
import matplotlib.pyplot as plt
# runs on CPU
# Hyperparameters
n = 5
m = 20
p = 500
sig = 0.1
K = 20
itermax = 1000
nu = torch.logspace(-7, 0, K) # logspaced weights
# Play with the code: you can disable distillation
#nu = torch.zeros(K)
#nu[K-1] = 1.0
# define training data
torch.manual_seed(2)
mu = 50*torch.rand(n, 1)
H = torch.randn(n, p) + mu # H are generated around a true value mu
W = torch.rand(m, n)
Y = W@H + sig*torch.randn(m, p)
# define trainable parameters
Ah = torch.ones(n,K, requires_grad=True)
#Ah = torch.ones(n, requires_grad=True) # for tied weights
# define loss function
def loss_fn(Y, W, H):
return torch.norm(Y - W@H)**2
# define MU updates
def MU_update(W, Y, Xinit, itermax=1000, Xgt=None):
X = Xinit.clone().detach()
WtW = W.T@W
WtY = W.T@Y
loss = [loss_fn(Y, W, X)]
sup_loss = []
for i in range(itermax):
X = X*WtY/(WtW@X)
loss.append(loss_fn(Y, W, X)) # can be optimized using stored quantities
if Xgt is not None:
sup_loss.append(torch.norm(X - Xgt)**2)
return X, loss, sup_loss
# define unrolled MU updates
def NALMU(W, Y, Xinit, Ah, itermax=25, Xgt=None):
X = Xinit.clone().detach()
loss = [loss_fn(Y, W, X)]
WtW = W.T@W
WtY = W.T@Y
Xs = []
sup_loss = []
for i in range(itermax):
XAh = (X.T*Ah[:,i]).T
#XAh = (X.T*Ah).T # for tied weights
X = XAh*WtY/(WtW@X)
Xs.append(X)
loss.append(loss_fn(Y, W, X)) # can be optimized using stored quantities
if Xgt is not None:
supl = torch.norm(X - Xgt)**2
sup_loss.append(supl.detach().numpy())
return X, Xs, loss, sup_loss
# define optimizer
optimizer = torch.optim.Adam([Ah], lr=1e-2) # using the Adam optimizer for simplicity
# Training
for epoch in range(500):
optimizer.zero_grad()
Hinit = torch.ones(n, p)
H_est, Hs, _, _ = NALMU(W, Y, Hinit, Ah, itermax=K)
loss = sum([nu[i]*torch.norm(Hs[i] - H)**2 for i in range(K)]) # weighted loss
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f'Epoch {epoch}, Loss: {loss.item()}')
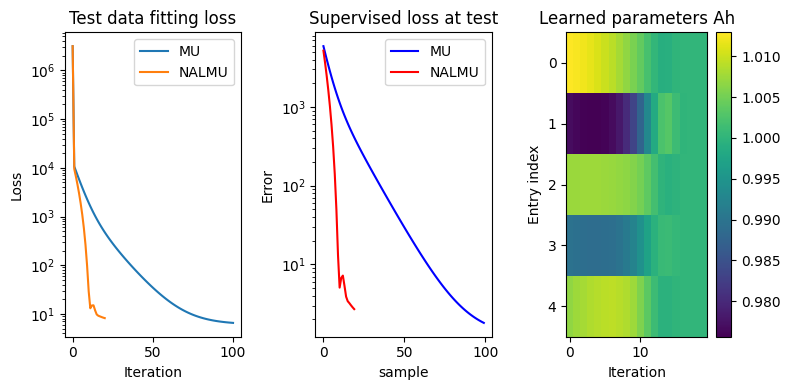
A few lessons to learn from this toy experiment:
The choice of the \(\nu_k\) values greatly affect how far the weights \(A_W\) are from one. With the proposed choice (logarithmically spaced values in \([10^{-7}, 1]\)), the weights in the last layers are barely updated. Try setting all \(\nu_k\) to zero except the last one: the result is reversed, and the overall performance of NALMU decreases!
Tied weights (when \(A_W\) does not depend on the iteration index) do not perform well in this example. This can be checked by changing the definition of \(A_W\) and updating the NALMU rule accordingly. In particular, NALMU with tied weights has difficulty reducing the NMF loss \(\|Y-WH^T\|^2\) over iterations.
Unrolling algorithms is tricky in practice, and one needs to toy with the various hyperparameters and design choices.