
Other perspectives#
The topics discussed in this section are scientific questions that I want to address, which are not directly related to the KL-divergence and Poisson noise.
Single-pixel imaging and compressive acquisition#
SPI has already been discussed in Single-pixel hyperspectral image reconstruction and unmixing. While the reconstruction algorithm is critical, to improve the overall algorithmic and hardware pipeline, the acquisition system is maybe even more important. The acquisition is modeled as a linear system \(y=Hx\), where the matrix \(H\) contains, in each row, the pattern of ones and zeros representing the micro-mirror positions at each acquisition. There are two relatively open questions regarding the choice of these patterns.
As discussed in Single-pixel hyperspectral image reconstruction and unmixing, the acquisition matrix coefficients have to belong to the interval \([0,1]\). The statistical optimality of Hadamard patterns holds for additive noise and entries in \([-1,1]\). There are other acquisition matrices, such as \(S\) matrices [Harwit and Sloane, 1979], that are shown to be optimal up to a factor \(2\). We are working on a research paper summarizing these ideas [Ducros et al., 2025]. Ongoing research in the team is also concerned with learning the acquisition patterns from a training dataset, or from the color camera in a multimodal acquisition setup. I will not explore this direction.
Once the patterns have been chosen, another question of importance is how to subsample the acquisition patterns to acquire \(y_S = H[S,:]x\), where \(S\) is the index set of acquired patterns. The compressive sensing literature informs how to choose these patterns, primarily by improving reconstruction with sparsity-based priors. Due to Poisson noise and the use of other reconstruction methods, in particular those based on deep priors, practical observations lead to a different policy for choosing the samples \(S\). A better understanding of the impact of acquisition patterns and acquisition subsampling on reconstruction performances is therefore needed. This topic is under scrutiny with Nicolas Ducros in collaboration with Laurent Jacques (UCLouvain), Marc Georges (ULiège), and Clément Thomas (PhD student ULiège).
Spectral unmixing dataset acquisition#
A problem that plagues signal processing research in hyperspectral imaging is the lack of reliable ground truth datasets. In remote sensing, where hyperspectral images often span several kilometers, it is simply not possible to go on the ground at the exact time the image was acquired and measure the spectra of each macroscopic element. Even if this were possible, the acquisition parameters, such as the incidence angle or illumination, impact the remotely acquired images. In hyperspectral microscopy, however, finer control over the scene may be possible. In Serena Hariga’s PhD thesis, we tried to print monochromatic shapes, hoping that the printer’s inks would be combinations of three primary colors, resulting in the predictable mixing of three components distributed spatially. However, the printer does not rely solely on additive mixing, and the printed image is therefore not rank three.
With Nicolas Ducros, we plan to design another acquisition protocol for hyperspectral microscopic images with controlled ground truth. One possible direction is to use several lamps to illuminate a black and white scene and rely on the additive spatial mixing of the two lights. The challenge would be to control precisely the spatial distribution of each light in the scene.
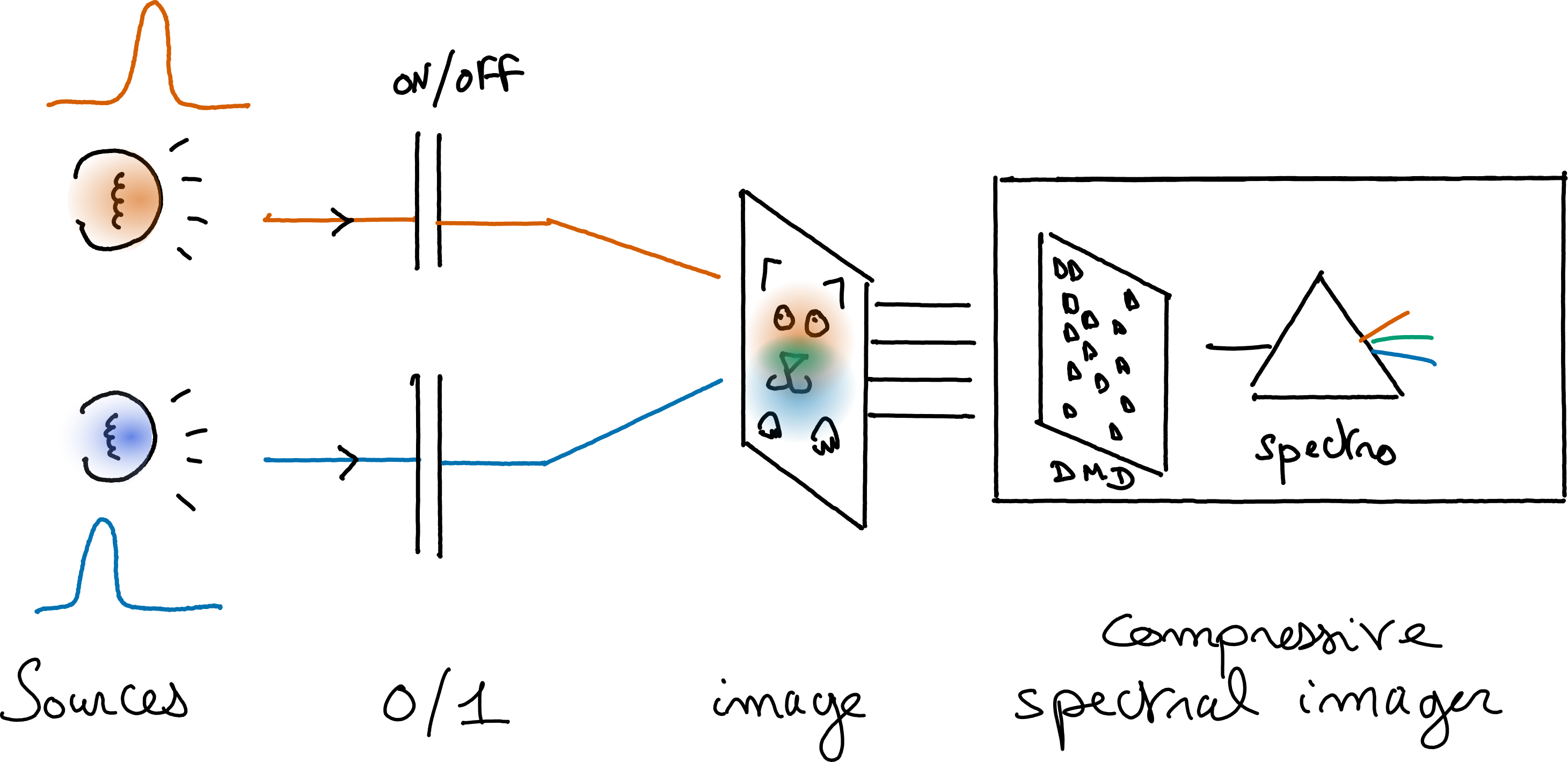
Fig. 39 Schematic illustration of the acquisition of a dataset for spectral unmixing in microscopy. Two lamps with different spectra are used to illuminate the same scene (a black and white image), and their spatial distribution partially overlap. This overlap produces a spatially varying additive mixture of the two spectra. The scene is acquired with any spectral imager such as the single-pixel spectral camera available at CREATIS. It is possible to obtain the ground-truth abundances for each component by shutting either one of the lamp. For instance, shutting down the red lamp means that we can acquire the abundances for the blue spectrum only. The challenge is to control rather accurately the spatial distribution of the illumination for each lamp, and to mitigate nonlinearities and experimental variability.#
Inverse problems and separable NMF#
Once the single-pixel data has been acquired, one may want to perform the reconstruction and the spectral unmixing jointly. This is the research project of Serena Hariga, currently finishing her PhD. We are designing Primal-Dual algorithms with data-driven priors that yield complicated algorithms even when spectral unmixing is not blind (the matrix \(W\) containing the spectra is known). In the future, we aim to develop a stable algorithm for reconstructing and performing blind spectral unmixing. One important missing step is a good initialization algorithm.
A powerful way to initialize NMF in other contexts is by performing separable NMF. Separable NMF searches for the spectra directly in the data matrix. However, in the context of inverse problems, this data matrix is not available. Ignoring the Poisson nature of the noise, the inverse separable NMF model may be formalized as the following optimization problem:
where \(Y\) is the spectral measurement matrix, \(H\) the acquisition matrix, \(S\) the indices of the pure pixels in the reconstructed matrix \(X\) and \(g(X)\) is some regularization, typically data-driven. The issue with this simple formulation is that it is unclear how to derive a fast algorithm to compute the solutions. The strength of separable NMF lies in the fact that algorithms such as SNPA [Gillis, 2014] that solve it are computationally cheap.
There are several ways to solve this issue. First, in the case where the acquisition matrix \(H\) is orthogonal, one may simply run separable NMF on \(H^TY\). But as soon as the patterns are subsampled, this strategy may not perform well. Our goal is therefore to improve the reconstruction pipeline compared to a two-step strategy, in which reconstruction and separable NMF are performed sequentially. Another possible direction is to use other variational formulations of separable NMF recently proposed [Pan et al., 2025]. It may be possible to design a fast algorithm for inverse separable NMF when the regularization \(g\) is ignored or is simple enough.
The core problem behind inverse separable NMF is that performing spectral unmixing in the measurement domain of an inverse problem is inherently difficult. Indeed, spectral unmixing relies heavily on the geometry of the data: the true spectra form a cone containing the data, which can often be observed directly by plotting the data. The forward operator of an inverse problem mixes all the data points, and the geometry of the problem is consequently heavily modified. Whether it is possible and useful to perform spectral unmixing on the measurement coefficients using a geometric algorithm is an open question.
Borgen plots revisited#
Many theoretical results on the identifiability of rLRA models exist, allowing a priori selection of the model and constraints adapted to a given practical signal processing problem. While these results are very useful, in most practical cases, they cannot be applied, as some of the quantities required to prove uniqueness are unknown or difficult to estimate. Another important line of work concerns a posteriori methods to check if the solutions to an inverse problem or rLRA optimization algorithm are unique. I believe this line of work has been largely ignored by the community despite its obvious usefulness for practitioners.
There is a small but deep literature on numerical algorithms for the visualization of solutions to NMF in small ranks (less than four) from the chemometrics community [Borgen and Kowalski, 1985], see [Neymeyr and Sawall, 2018] for a mathematical survey. Borgen and Kowalski proposed what is now sometimes called Borgen plots; see Fig. 40 below for an illustration with the rank-three case. The set of solutions to NMF is parameterized explicitly with \(r-1\) parameters as
where \(T\) is a \(r\times r\) invertible matrix. The trick to Borgen plots is to note that scaling and permutation ambiguities can be leveraged to restrict the parameterization of the matrix \(T\) to that of its first row, and that its first column may be set to 1. Therefore, the set of feasible solutions is parameterized in the rank three case by only two parameters \(\alpha_1\) and \(\alpha_2\), and exhaustive search for all equivalent solutions is reasonably doable. This was proposed rather recently in 2011 by A. Golshan, H. Abdollahi, and M. Maede [Golshan et al., 2011], using covering triangles. It is possible to show other properties on the set of feasible NMF solutions that fasten this process. For instance, the set of solutions is a convex polytope. A MATLAB toolbox exists that provides efficient numerical algorithms for computing Borgen plots [Sawall and Neymeyr, 2014] Facpack website.

Fig. 40 A schematic illustration of the information provided by Borgen plots. On the left, several solutions of NMF are illustrated in the source domain. Several examples of the three components estimated by a rank three NMF are superposed. Borgen plots reduce the dimensionality of the set of solutions to a 2D space parameterized by \(\alpha_1\) and \(\alpha_2\) thanks to SVD and the clever use of symmetries in the problem. The set of solutions are now represented by three polytopes. In this examples, the first component \(W[:,0]\) can be uniquely recovered from the data, but the other two components are not identifiable.#
Borgen plots are an amazing tool for visualisation of NMF solutions a posteriori. However, there are several problems with them. Most importantly, they have been designed for very small ranks. Visualization becomes more difficult at higher ranks, and as rank and dimensions increase, the numerical strategies based on exhaustive search become intractable. The cost of verifying the validity of a matrix parameterized by the vector \(\alpha\) also involves solving a small matrix inversion problem, which can be costly in higher dimensions. Consequently, there is room for the development of methods that scale to higher dimensions [Sawall et al., 2026]. Another issue is that the current design of Borgen plots may return infeasible solutions, and that some solutions may be ignored in the visualization if the data is reducible (in which case the Perron-Frobenius theorem does not apply), or if the set of solutions has several disconnected convex subsets (because the geometric construction of the feasible set works locally).
Beyond NMF, I want to extend numerical representations of solution sets to other inverse problems. One possible direction is to work in the null-space of the Jacobian matrix, as proposed by Nathanaël Munier, Emmanuel Soubies, and Pierre Weiss [Munier et al., 2025].