
Extrapolated BCD algorithms for unconstrained matrix and tensor decompositions#
Reference
[Ang et al., 2019] A. Ang, J. E. Cohen, L. K. Hien, N. Gillis, “Extrapolated Alternating Algorithms for Approximate Canonical Polyadic Decomposition”, ICASSP2020, pdf.
[Ang et al., 2020] A. M. S. Ang, J. E. Cohen, N. Gillis, L. T. K. Hien, “Accelerating Block Coordinate Descent for Nonnegative Tensor Factorization”, Numerical Linear Algebra Appl., 2021;e2373. pdf
Among various techniques to speed up first-order optimization algorithms for convex smooth problems, extrapolated (also called inertial) algorithms are especially popular. The theory of extrapolated algorithms such as Nesterov projected gradient descent (also called FISTA or inertial Forward Backward) is now rather well understood: while the convergence rate of gradient descent for smooth strongly convex cost functions is at worse \(\mathcal{O}(\frac{1}{k})\), Nesterov gradient descent converges with rate \(\mathcal{O}(\frac{1}{k^2})\). This improvement comes at almost no additional cost in terms of memory or computation. In essence, extrapolated first-order algorithms minimize a cost function \(f(x)\), where \(x\) must belong to a convex set \(\mathcal{C}\), with iterates of the form
where \(y_{k}\) and \(x_{k}\) are the auxiliary and principal sequences of iterations at iteration \(k\), \(\eta\) is the stepsize, \(\mathcal{\Pi}_{\mathcal{C}}\) is the projection on convex set \(\mathcal{C}\) and \(\alpha_k\) is an extrapolation parameter dependent on the iteration index. Various formulations have been proposed for the choice of \(\alpha_k\). The convergence of such a scheme was proved first by Nesterov [Nesterov, 1983], but later analyzed more generally as discretized second-order differential equations [Attouch and Peypouquet, 2016]. Interestingly, the cost function may increase with Nesterov gradient descent. O’Donoghue and Candès have proposed a restart strategy to further speed up convergence [O’Donoghue and Candes, 2015]. Restart consists in resetting the value of \(\beta_k\) to ensure that the cost decreases.
Extrapolated block-coordinate algorithms for LRA#
Extending inertial extrapolation strategies for LRA is not straightforward. Indeed, extrapolated algorithms were initially proposed for convex problems, but LRA optimization problems are, in general, multiblock and nonconvex. A simple approach would be to use extrapolated algorithms to solve each block in an alternating algorithm. In [Ang et al., 2019] and [Ang et al., 2020], we proposed an empirical strategy to perform extrapolation for BCD algorithms after the BCD updates, at the outer loop level. In other words, we extrapolate the estimated block of variables after the update, using the previous block estimate. This is fundamentally different from extrapolation within each block. This work has spurred a series of more principled works, in which I was not involved, led by Lee Ti Hien Khan and Nicolas Gillis, that propose extrapolated BCD algorithms with convergence guarantees and good empirical performance [Hien et al., 2023], [Hien et al., 2025]. Other works in the literature have studied extrapolated block coordinate descent; see, for instance, the iPALM algorithm [Pock and Sabach, 2016]. The main difference between iPALM and subsequent works by Khan, in particular TITAN, is that iPALM alternates between extrapolated gradient steps, whereas TITAN studies a broader class of alternating inertial MM algorithms, including iPALM.
Another work, published almost simultaneously and closely related to ours, proposes an extrapolated ALS algorithm for CPD with restart [Mitchell et al., 2020].
Heuristic Extrapolation with Restart#
The Heuristic Extrapolation with Restart (HER) framework takes the idea of Nesterov projected gradient but applies it to a full BCD cycle. For simplicity, let us apply the HER framework to a specific model: nonnegative CPD,
A vanilla BCD algorithm for nCPD is ANLS, using a generic NNLS solver, which writes as follows for the \(k\)-th iteration:
In contrast, HER-ANLS extrapolates the estimates \(X^{k+1}\) based on the NNLS estimation and the previous value, both taken in a pairing sequence \(Y^{k}\), as follows:
To ensure that the cost function does not increase significantly, HER also performs a restart operation and updates the extrapolation hyperparameters in consequence. The following code implements HER-ANLS, simplified from the presentation in [Ang et al., 2020], which used an additional pairing sequence to ensure that the cost function decreases.
# HER-ANLS
def HER_ANLS(data, rank, cp_e, beta=0.1, gamma=1.05, eta=2.0, itermax=100):
"""
HER-ANLS: Heuristic Extrapolated Alternating Nonnegative Least Squares for Nonnegative Canonical Polyadic Decomposition (nCPD).
"""
# Initialize factor matrices and auxilliary factor matrices
cp_y = deepcopy(cp_e)
# Initialize hyperparameters
norm_tensor = tl.norm(data, 2)
err = [tl.norm(data - cp_e.to_tensor())] # Initial error.
# Outer iteration loop
for k in range(itermax):
# loop on the modes of the tensor
for mode in range(data.ndim):
# Computing MTTKRP and pseudo-inverse
pseudo_inverse = get_pseudo_inverse(cp_e, rank, mode, data)
mttkrp = unfolding_dot_khatri_rao(data, cp_e, mode)
factor_old = np.copy(cp_y[1][mode])
# Call the hals resolution with nnls, optimizing the current mode, inplace update
hals_nnls(
tl.transpose(mttkrp),
pseudo_inverse,
tl.transpose(cp_y[1][mode]),
n_iter_max=100,
)
# Extrapolation step, store temporarily to check for restart
cp_e[1][mode] = tl.maximum(
cp_y[1][mode] + beta * (cp_y[1][mode] - factor_old), 0
)
# Check for restart
current_err = err_calc_simple(cp_e, mttkrp, norm_tensor)
if k>0 and current_err > err[-1]:
## Restart the extrapolation, cost increased
cp_e = deepcopy(cp_y)
beta = beta/eta # decrease beta
err.append(tl.norm(data - cp_e.to_tensor())/norm_tensor)
else:
## More aggressive extrapolation
beta = tl.minimum(beta*gamma, 1) # increase beta
err.append(current_err)
return cp_e, err
Let us test the HER-ANLS algorithm on a simple nCPD problem with small dimensions and almost no noise.
# Hyperparameters
rank = 2
dims = [6,6,6]
noise = 1e-7
# Generate a random nCPD problem
np.random.seed(42) # For reproducibility
cp_true = tl.random.random_cp(dims, rank) # rank 2, dim 10x10x10
cp_true[0] = None # no weights
init_cp = tl.random.random_cp(dims, rank)
init_cp[0] = None
for i in range(3):
cp_true[1][i] = tl.maximum(cp_true[1][i],0)
init_cp[1][i] = tl.maximum(init_cp[1][i],0)
T = cp_true.to_tensor() + noise*tl.random.random_tensor(shape=dims) # Add some noise
# Computing the nCPD with HER-ANLS
cp_e, err = HER_ANLS(T, rank, deepcopy(init_cp), itermax=100, beta=0.01, gamma=1.2, eta=5)
# Comparison with tensorly nn_cp hals
err_hals = []
def err_ret(_,a):
# non_negative_parafac_hals returns a tuple (cp, err, loss) with a 1/2 coefficient for the Frobenius norm
err_hals.append(a)
out2 = non_negative_parafac_hals(T, rank, init=deepcopy(init_cp), callback=err_ret, n_iter_max=100, tol=0)
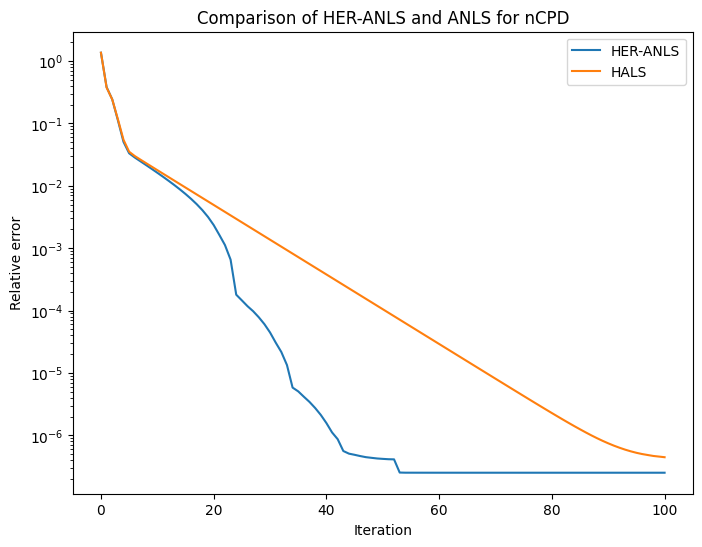
Note that the main hyperparameters for HER-ANLS are
\(\gamma\): the amount by which the extrapolation parameter is multiplied at each iteration.
\(\eta\): the amount by which the extrapolation parameter is divided when restart occurs.