
Numerical optimization for KL-based regularized inverse problems#
The primary focus of my research over the past decade has been on rLRA. rLRA is a discipline at the intersection of inverse problems, statistics, numerical optimization, and machine learning, with diverse applications such as music information retrieval and spectral imaging that require specialized expertise. While I have always enjoyed embracing the diversity of the mathematical tools required to make contributions to rLRA, in the coming years, I want to focus especially on numerical optimization, with potential contributions beyond rLRA. I enjoy the idea that, in numerical optimization, there is often a clear problem-solving objective, such as cost minimization or speed maximization, that allows us to compare methods. I also enjoy the mathematical framework of both smooth and discrete optimization problems and algorithms. Numerical optimization provides an opinionated view of the world, as many tasks can be expressed in this framework. On the mathematical side, theoretical results and proofs are both intuitive and rigorously enunciated.
A family of problems that I want to study in particular, related to nonnegativity of the parameters and data, is KL-divergence-based estimation, such as NN-KL. KL-divergence is a rich loss function to study because it lacks Lipschitz-smoothness at zero (its gradient tends to infinity), but it is also asymptotically flat towards infinity. This makes the design of global strategies, such as gradient descent with a fixed stepsize or global majorization-minimization, rather difficult. In what follows, I explain why the KL-divergence arises in inverse problems, what the hypotheses and challenges of my research project are, and its position in the state-of-the-art. I then detail the various contributions I have in mind for the coming years with identified collaborators.
Other, smaller-scale aspects of my research project are detailed in a separate section. This section contains redundant information on the basic mathematical tools described in the rest of the HDR manuscript to ensure that it can be read independently, to some degree.
Scientific context#
KL-divergence, a fundamental measure of similarity between probability distributions in machine learning, naturally arises from Poisson maximum likelihood models [Fessler, 1995], but also provides a robust measure of discrepancies compared to the Euclidean norm. This robustness is particularly relevant for audio spectrograms that exhibit large dynamic ranges and for low signal-to-noise ratio counting processes, which could be considered the future of many existing computational imaging devices, offering reduced acquisition time. KL-divergence between two vectors \(y\) (the data) and \(Ax\) (the unknown) in \(\R{n}_+\) is defined as
Inverse problems aim at estimating physically meaningful parameters (images, audio representations, sources) from incomplete and noisy data. In this research project, I focus on two problems: Nonnegative KL regression problems (NN-KL) and Nonnegative matrix and tensor KL factorization problems (NMF-KL). See the dedicated chapter on NN-KL and Fig. 38. NN-KL reconstructs or denoises images in many computational imaging applications such as tomography, Compton camera, cryoEM, and single-pixel imagers [Green, 1990, Hariga et al., 2025]. NMF-KL is a linear dimensionality reduction technique similar to PCA, where nonnegativity ensures an interpretable part-based representation [Hien and Gillis, 2021, Kervazo et al., 2024, Modrzyk et al., 2025]. NMF-KL is also a blind extension of NN-KL and has been used extensively to analyse spectrograms found in music information retrieval tasks, in particular to perform Automatic Music Transcription that translates music recordings into MIDI files (numerical music sheets) [Wu et al., 2022]. NN-KL and NMF-KL problems are generally ill-posed: there are too few measurements or too much noise to uniquely and precisely recover the unknowns, which compromises interpretability. Regularization is thus essential. It can be introduced via handcrafted priors (e.g., sparsity, smoothness), via pre-trained priors using Plug-and-Play (PnP) denoisers, or Unrolled algorithms that exploit training datasets [Hurault et al., 2023, Kervazo et al., 2024, Le Roux et al., 2015].
Hypotheses and challenges#
I hypothesize that it is possible to design algorithms that are both fast and provably convergent for KL-based regularized inverse problems. Purely from a smooth numerical optimization perspective, the main difficulties are
The lack of Lipschitz smoothness at zero of the KL-divergence, which causes instabilities with sparse data or low counts when using first-order methods. This explains why most existing approaches rely on second-order information, typically through separable quadratic surrogates derived from Hessian approximations.
The asymptotic linearity of the KL-divergence, encountered when the term \(Ax[i]\) dominates the cost, and in particular when the data has many zeros. The objective flatness makes any gradient-based algorithm hard to use: the cost is not strongly convex, and the Hessian has near-zero singular values. Both these issues are known to imply slower convergence.
The presence of nonnegativity constraints, as well as other regularizations, possibly based on deep learning. Our challenge is twofold. First, to optimize the design of algorithms for NN-KL and NMF-KL, striking the right balance between accuracy and per-iteration cost. I plan to rely on local (rather than global) approximations of the cost function and on tools from linear programming. Local majorants are expected to work well because they do not need to diverge at zero, but their asymptotic flatness, in particular for sparse data, must be handled carefully. Second, to extend these strategies to include data-driven regularizations, which fall within variable metric forward–backward methods and remain difficult to implement for both handcrafted and data-driven priors [Chouzenoux et al., 2016]. Beyond algorithm design, I will unify contributions scattered across numerical optimization, source separation, and computational imaging, producing a benchmark and a toolbox for KL-based inverse problems. The methodology will be validated on two applications where I have strong expertise: SPI and AMT [Kervazo et al., 2024, Wu et al., 2022]
Positioning with respect to the state of the art#
MU, or ML-EM in computational imaging, remains the historical baseline for KL-based problems. MU is simple to implement and uses second-order information via preconditioning. It is a baseline that can be slow, unstable for sparse data, and difficult to adapt with regularizations. However, it is not so easily beaten, especially in the context of NMF-KL [Hien and Gillis, 2021]. MU has a wide number of variants, some of which have been developed in the computational imaging community and involve block-coordinate updates [Erdogan and Fessler, 1999, Fessler, 1995, Green, 1990], while others come from the signal processing community and focus, for instance, on all-at-once updates for wider classes of loss functions [Marmin et al., 2023] or high-order tensor decompositions [Hood and Schein, 2026]. Most algorithms for NN-KL and NMF-KL, including MU, fall within the majorization-minimization framework, where the cost is globally majorized by a simpler function, often separable with respect to each parameter, and the majorant is then minimized efficiently. I will use local approximations that do not fall within the majorization-minimization framework.
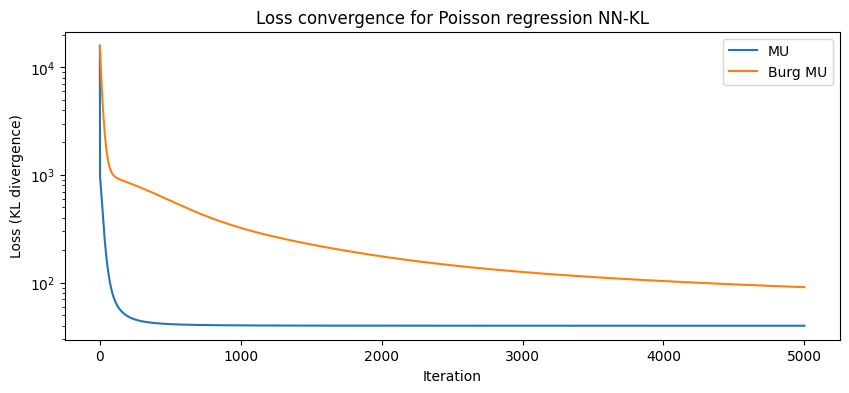
Classical constrained formulations lack a general framework for KL-based problems. MU can be applied, after non-trivial modifications, for a limited set of priors such as \(\ell_p\) norms and TV regularization. Data-driven approaches (Plug-and-Play, Unrolled NMF) are promising for achieving state-of-the-art performance while ensuring model interpretability, yet their KL-based theoretical grounding is weak. In particular, PnP algorithms for KL-divergence rely on a loose Bregman divergence, Burg’s entropy, resulting in poor convergence speed [Bauschke et al., 2017, Hurault et al., 2023]. Burg’s entropy is used in proximal mirror descent to build a global majorant of the cost, but it can be observed on the following simple synthetic example that MU is typically much faster than Burg’s entropy. Damien Lesens has also shown, in a personnal communication, that the majorant of MU is optimal within the set of separable majorants and is therefore always better than the majorant relying on Burg’s entropy. The reason why Burg’s entropy is used despite its loose majoration of the KL-divergence is that it is unclear how to relate the majorant leading to MU or other existing faster algorithms with proximal mirror gradient descent, and therefore obtain a clean setup for non-Euclidean data-driven algorithms. I hypothesize that such links can be obtained, and that other frameworks than mirror gradient descent may be used for convergent data-driven non-Euclidean algorithms.
from matplotlib.pylab import f
import numpy as np
# Let's compare MU and Bregman mirror descent on a simple Poisson regression problem
# Hyperparameters
m, n = 100, 20 # number of samples and features
alpha = 100 # Poisson signal level
hgt = np.maximum(np.random.randn(n),0)
W = np.random.rand(m,n)
y = np.random.poisson(alpha * W @ hgt)
def loss(h): # KL divergence
return np.sum(W@h-y) + np.sum(y * np.log((y+1e-10)/(W @ h)))
def MU(y, W, h, itermax=1000, epsilon=1e-10):
Wtsum = W.T @ np.ones_like(y) # suboptimal but ok
hout = np.copy(h)
loss_val = [loss(hout)]
for i in range(itermax):
hout = np.maximum(epsilon, hout * (W.T @ (y / (W @ hout ))) / (Wtsum))
loss_val.append(loss(hout))
return hout, loss_val
def BurgMU(y, W, h, itermax=1000, epsilon=1e-10): # NoLIPS by Bauschke et al
Wtsum = W.T @ np.ones_like(y)
lamb = 1/2/np.sum(y)
hout = np.copy(h)
loss_val = [loss(hout)]
for i in range(itermax):
hout = np.maximum(epsilon, hout / ( 1 + lamb* hout * ( Wtsum - W.T @ (y / (W @ hout )))))
loss_val.append(loss(hout))
return hout, loss_val
hmu, loss_mu = MU(y, W, alpha*np.ones(n), itermax=5000)
hburg, loss_burg = BurgMU(y, W, alpha*np.ones(n), itermax=5000)
# Printing the final estimation error
print(f"Final loss MU: {loss_mu[-1]}, Burg MU: {loss_burg[-1]}")
print(f"Estimation error MU: {np.linalg.norm(hmu - alpha*hgt)/np.linalg.norm(alpha*hgt)}, Burg MU: {np.linalg.norm(hburg - alpha*hgt)/np.linalg.norm(alpha*hgt)}")
Final loss MU: 39.89496205378027, Burg MU: 90.91379149716423
Estimation error MU: 0.07401607329016432, Burg MU: 0.21682081046000845
Finally, existing algorithms are designed for small, dense matrices, whereas audio applications also lead to sparse, large matrices. In summary, no existing method simultaneously achieves speed, robustness to data sparsity, and theoretical guarantees, leaving a clear gap that I aim to fill.
Methodology and scientific coverage#
The research project is divided into four complementary subtasks to achieve the global objective of conceiving faster regularized algorithms for KL-based inverse problems, see Fig. 38. It is grounded in the numerical optimization community, but with strong interactions with the machine learning and signal processing communities.
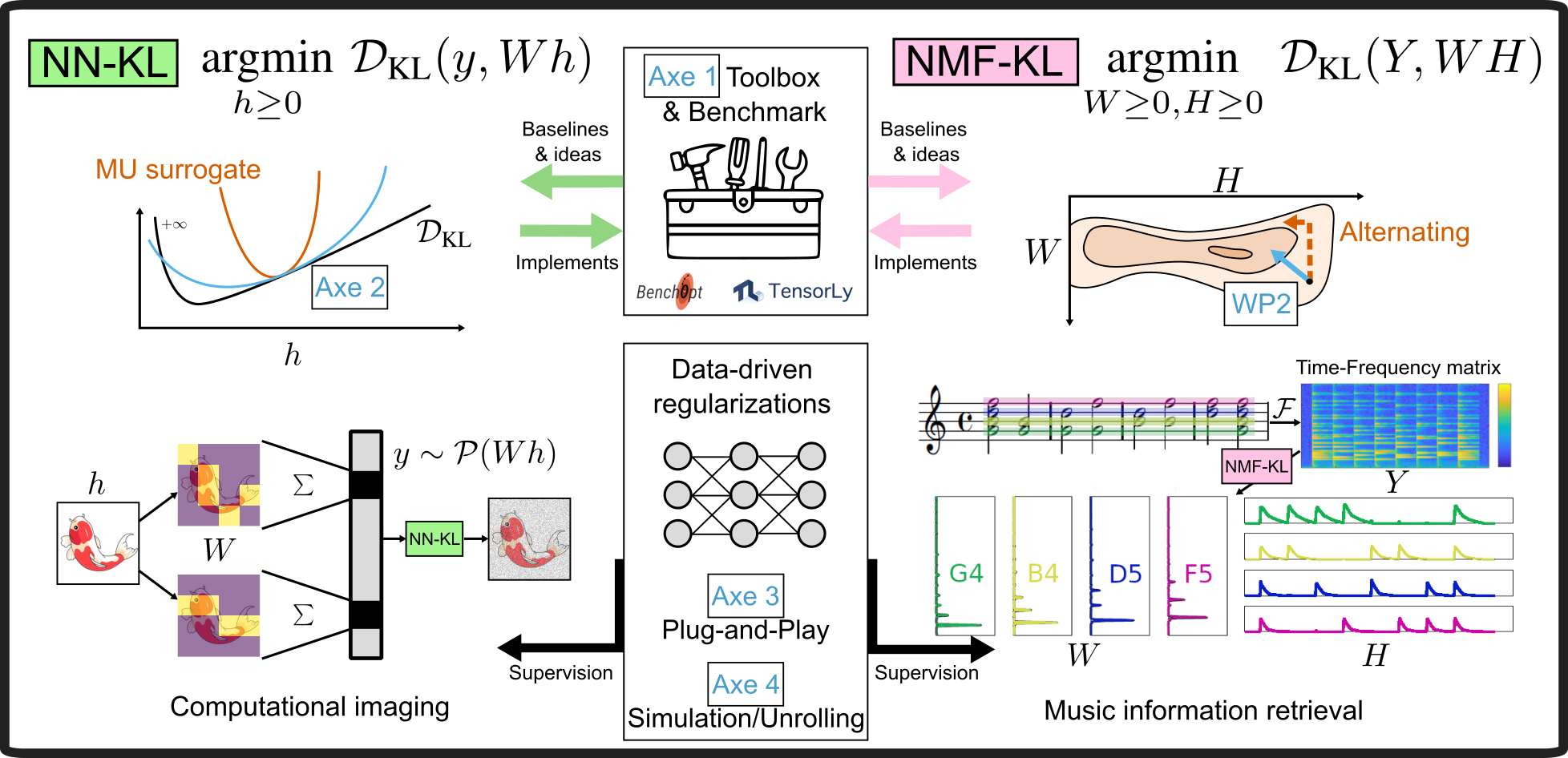
Fig. 38 Schematic organisation of my research project, its connections with numerical optimization and inverse problem in spectral imaging and music information retrieval.#
1. NMF toolbox and benchmark#
As of early 2026, it remains far from straightforward to navigate the world of NMF algorithms for researchers and end users alike. On the side of models, there are several loss functions to choose from depending on the data type and noise distribution, and various regularizations can be considered. Even for a bare-bones model such as NMF-KL, the literature does not clearly specify which algorithm to use in which context. Choices to be made have several layers of complexity: should the algorithm alternate over the two parameter matrices, or update both simultaneously? Should one use a majorization-minimization algorithm such as MU, a primal-dual algorithm, mirror descent with Burg entropy, or a second-order-inspired algorithm such as the proposed mSOM? Are extrapolation and momentum needed? The actual performance gap between these methods depends heavily on the application at hand. In particular, in the context of NMF-KL for document mining or audio processing, data sparsity and data size can be critical, and the implementation of algorithms (sparsity handling, efficient caching of operations) matters.
I believe that performing meaningful research on NMF-KL algorithms requires first taking a step back and analyzing precisely the current state-of-the-art. In particular, I plan to build a benchmark for NMF models, starting with NMF-KL, that includes as many algorithms from the literature as possible, and datasets publicly available from applications in document mining, music information retrieval, hyperspectral imaging in remote sensing and microscopy, computer vision, and chemometrics. The backbone of the benchmark was already developed in 2022 in collaboration with Cassio Fraga-Dantas, relying on Benchopt [Moreau et al., 2022], but needs to be enhanced with algorithms and a dataset.
Alongside the development of this benchmark, the implementation of existing algorithms will be made available in a dedicated NMF toolbox in Python, along with other useful tools such as separable NMF algorithms and Borgen plots discussed later in the perspectives, and an integration of efficient implementations in a lower-level language of important routines such as AS and HALS. Available Python packages for NMF include scikit-learn, which implements only multiplicative updates for NMF-KL, and Nimfa, a toolbox no longer maintained that focuses on model diversity (including many Bayesian and graph-regularized variants of NMF) rather than on efficient algorithms for a few targeted models. The proposed NMF toolbox may rely on tensorly to be backend-agnostic (allowing lower-level operations to be performed transparently by NumPy, PyTorch, JAX, etc.). The architecture of the package is not yet decided, and it may be built on top of only PyTorch for simplicity and support for auto-differentiation, or in Julia for better integration of efficient sparse-oriented routines such as sparse NNLS.
Collaborators: The benchmark is already under construction by Damien Lesens (ENS Lyon, LIP) as part of his PhD thesis, co-supervised with Bora Uçar (CNRS, LIP). It will be completed by me and all supervised students working on problems related to the KL-divergence. Collaborators from Telecom Paris (Christophe Kervazo, Mathieu Fontaine, Roland Badeau) and IMT Atlantique (Quyen Pham) are also expected to participate. If this benchmark finds echo in the NMF community, other research groups may join the initiative, such as the group of Nicolas Gillis in Mons that lacks such a unified software platform.
2. New numerical optimization tools for faster NN-KL and NMF-KL#
NN-KL is a rather old optimization problem, and both researchers and users (in particular those in computational optics) have proposed numerous ideas for designing fast and accurate solvers. One key scientific lever has been the design of global majorants of the KL-divergence, in direct relationship with the EM framework. In this context, it may seem unrealistic to assert that my collaborators and myself will propose faster algorithms for NN-KL. NMF-KL has been studied less than NMF, since NMF is far less commonly used than linear regression, but the same observation could be made.
This research project is built on the idea that some important research directions in optimization with the KL-divergence have not been explored. First, there are relatively few methods that do not rely on global MM. While MM is useful for designing convergent algorithms, the geometry of the KL-divergence, which diverges at zero yet is asymptotically linear, makes it difficult to design majorants that are both global and tight. Popular majorants such as those used in MU are also separable. Recent works on regularized NN-KL and NMF-KL based on mirror gradient descent use Burg’s entropy to construct a majorant, which is worse than the MU majorant. One promising research direction is to resort to local separable majorants using second-order information. In an ongoing work with Mai Quyen Pham and Thierry Chonavel [Pham et al., 2025], we show that we can design local majorants of the cost by building diagonal majorants of the Hessian matrix iteratively, of the form
where \(H(x)\) is the Hessian matrix at point \(x\) and \(u\) is a vector that represents a diagonal matrix from this class. For any positive \(u\), it can be shown that \(M(u,x) - H(x)\) is symmetric and definite positive. In other words, we can build a local majorant of the cost with curvature given by the matrix \(M(u,x)\). Diagonal approximations of the Hessian matrix allow decoupling of the parameters in the minimization of the majorant, which is important for scalability. Our work opens many perspectives, as we study a single class of local majorants, and pick a particular item in that class that can be obtained in closed form. We plan to find even better local majorants by solving small-scale optimization problems. We also plan to extend this strategy to all-at-once algorithms and explore similar ideas within the framework of mirror descent.
Second, KL-divergence has a linear term \(\sum_{i,j} A[i,j]x[j] - \sum_{i} y[i]\), that links NN-KL with linear programming. More precisely, the KKT conditions show that, at optimality, this sum must cancel out. This allows us to replace the linear term in the KL-divergence minimization problem with a linearly constrained problem
I hypothesize that it can be used to build efficient algorithms for sparse NN-KL and sparse NMF-KL problems. Indeed, if most entries of the data vector \(y\) are null, the problem is similar to an interior-point method for linear programming with a logarithmic barrier function. It is therefore tempting to associate NN-KL for sparse data with a linear program that could be used to initialize other algorithms. It is also interesting to explore the use of the Sinkhorn algorithm to enforce this scaling within any alternating algorithm for NMF-KL, since these marginal constraints are, in general, not satisfied during the iterations. Finally, second-order methods will be considered since the Hessian matrix should be highly structured, and linear constraints can be incorporated. Most algorithms on the market simply ignore the possibility that the data matrix and/or the parameters can be extremely large and extremely sparse. While most algorithms can be easily adapted to handle sparse data, some are not so easy to adapt, such as primal dual algorithms, where the dual variables are generally dense.
Collaborators: The design of local majorants is the purpose of a long-term collaboration with Mai Quyen Pham (IMT Atlantique). We plan to continue working on this topic together by recruiting a PhD student. The study of the links between KL-divergence optimization and linear programming is the topic of Damien Lesens’s PhD thesis, co-supervised with Bora Uçar. The topic of optimization for KL-divergence and more generally Poisson-distributed data is currently under scrutiny by several research groups, including Voichita Maxim in my team at CREATIS, Lucas Calatroni (I3S, Nice and University of Genoa, Italy), Emilie Chouzenoux (Inria Saclay), Marceylo Pereyra (Heriott-Watt University, Edinburgh), Nicolas Gillis (UMONS, Belgium), and Shota Takahashi (University of Tokyo). This opens the way for new international collaborations. Research on nonnegative KL-divergence problems may also generalize beyond the realm of NMF to quadratic programming [Sha et al., 2007] and any nonnegative einsum factorization [Hood and Schein, 2026].
3. KL-based inverse problems for computational imaging#
Computational imaging has a long history of handling Poisson noise in inverse problems, probably more so than any other field within the scope of signal processing. Historically, Poisson noise was handled by a variance-stabilizing transformation (Poisson noise variance depends on the signal). The Anscombe transform is such a transformation of the data entrywise so that the noise distribution becomes Gaussian with a uniform variance. Variance-stabilizing transformations have the advantage of being fast at inference, since the forward and inverse transformations are cheap, and algorithms solving inverse problems with Gaussian noise are generally significantly faster than their KL-divergence counterparts. The Anscombe transform and other similar techniques, however, suffer in the presence of low-count data. KL-divergence is the loss function that appears when computing the MLE for inverse problems with Poisson noise. While it does not introduce statistical errors like variance-stabilizing transformations, it leads to significantly more expensive algorithms.
In modern signal processing and machine learning algorithms for inverse problems, we build on classical estimation algorithms, such as NN-KL solvers, using prior information provided by deep models. The general idea is that a neural network can be trained on denoising problems to learn the distribution of clean data, which in turn allows the construction of efficient priors for other inverse problems. The Plug-and-play (PnP) framework [Venkatakrishnan et al., 2013] simply plugs a pretrained network in place of a proximal (projection) operator in iterative proximal gradient algorithms, while other methods like RED [Liu et al., 2021] use differentiable architectures plugged in the cost function.
It is important to acknowledge that, while these data-driven techniques significantly improve the estimation performance of algorithms in inverse problems, they inherit the ups and downs of classical methods from which they are built. I believe that, while fellow researchers have focused on improving the data-driven aspect of data-driven algorithms for Poisson inverse problems based, for instance, on generalized Tweedie’s formula [Efron, 2011], the interplay between deep regularizers, classical methods including variance stabilizing transformations, and specific computational imaging applications is under-explored. There is probably no need for data-driven KL-divergence-based algorithms for high-count data when the Anscombe transform can be applied without issue. In contrast, there is a clear need for a more detailed analysis of when to use heavy computational tools, such as PnP, with complex NN-KL solvers. Nevertheless, part of this project is also to develop such data-driven Poisson algorithms; this is ongoing work within Serena Hariga’s PhD thesis [Hariga et al., 2024, Hariga et al., 2025].
We will target our contributions towards the computational imaging modalities developed at CREATIS, in particular spectral SPI. SPI is interesting because the Poisson noise level depends on the acquisition technique and on the output wavelength. The energy of incoming photons is split between spectral bands, and some spectral bands receive significantly fewer photons than others. This kind of data is perfect for analyzing the effect of signal noise on estimation performance. Moreover, the spectral data require unmixing, which can be performed efficiently with NN-KL or NMF-KL in the blind case, inside the reconstruction problem. In the blind case, the problem of estimating sources and abundances in SPI can be formulated as
where \(H\) is the acquisition matrix (such as Hadamard patterns), and \(g_i\) are deep or classical regularizations required to ensure interpretability of the results and proper image reconstruction. A particularity of SPI is that the noise can be modeled as a mixture of Poisson and Gaussian noise, for which the exact MLE is not known in closed form and is often approximated using variance-stabilizing transformations [Anscombe, 1948, Fryzlewicz and Nason, 2004, Makitalo and Foi, 2011, Makitalo and Foi, 2011, Bar-Lev and Enis, 1988]. Other interesting modalities include the spectral CT scanner, compton camera, and cryo-EM [Singer, 2018].
Algorithms developed in the second research direction will also be good candidates for extensions to the data-driven framework. Some authors focus on Burg’s entropy for building data-driven algorithms with Poisson noise [Hurault et al., 2023], but better results should be achieved by considering better majorants of the KL-divergence, at the cost of more difficult convergence proofs.
Collaborators: SPI is the topic of an ongoing, fruitful collaboration with Nicolas Ducros (INSA Lyon, CREATIS). The PhD thesis of Serena Harriga, co-supervised with Prof. Ducros, which started in 2023, focuses on primal-dual data-driven algorithms for SPI. At the national level, joint spectral unmixing and inverse reconstruction in the context of Poisson noise is one of the topics discussed in an ANR project under construction with HORIBA, a spectrometer manufacturer, and in collaboration with the DyNaChem team of the LASIRE (Lille). The Poisson-Gaussian noise and equivalences are a point of common interest with Valentin Debarnot, recently recruited to the team.
4. Automatic transcription using NMF-KL, neural architectures, and unsupervised learning#
NMF has a 20-year history of use in music information retrieval. One of its first use cases, which has remained an application of choice for NMF, is Automatic Music Transcription (AMT) [Smaragdis and Brown, 2003]. NMF has shown promising performance for AMT, in particular when KL-divergence (and other \(beta\)-divergences) are used as loss functions. It has been outperformed by deep networks trained end-to-end for almost a decade [Hawthorne et al., 2018].
Deep learning for AMT leverages training samples. The raw comparison with NMF, which has been used as an unsupervised model in AMT, is unfair. However, it is not clear at all how NMF could benefit from training samples. I have identified two promising routes.
First, one may use the unrolling framework to train parts of NMF for AMT. With Christophe Kervazo, we have recently proposed unrolled MU updates, with application to spectral unmixing. Our preliminary experiments on unrolled NMF for AMT show that this application is quite challenging because audio data size, sparsity, and dynamics pose challenges for current approaches. It should be possible to define a suitable unrolled state-of-the-art algorithm, a training procedure, and compare symmetric unrolling (both W and H) to older approaches that unroll H as a function of W [Le Roux et al., 2015].
Second, training deep networks for AMT, and in fact for most music information retrieval tasks, is costly in terms of the amount of training data required. While training data are available for some instruments, such as the piano, thanks to acoustic instruments with activation sensors (Yamaha Disklavier), for rare instruments, it is unlikely that such a database can be acquired in the coming decades. Therefore, there is still room for unsupervised learning algorithms for AMT. NMF models have seen several refinements in recent years regarding identifiability (minimum volume, separability, and, of course, better NMF-KL algorithms) that can be helpful in their fruitful application to a source separation problem like AMT. I will also go further by leveraging both recent NMF developments and Differential Digital Signal Processing, a state-of-the-art framework for unsupervised learning in deep learning for audio. DDSP essentially trains encoder networks to play software synthesizers and reproduce unlabeled instrument recordings, given the knowledge of pitch class and sound amplitude [Engel et al., 2020]. NMF could be trained alongside a DDSP model to serve as a generalized pitch-detection algorithm.
Research on AMT is, by nature, translational, and therefore it should be a priority to produce open-source software with a user-friendly interface and a Python backend that can be used to transcribe multi-instrument professional recordings, provided that the research is sufficiently fruitful to achieve satisfactory performance.
Collaborators: I started working on AMT with Nancy Bertin in Rennes, who is currently on leave from CNRS, and with Axel Marmoret, my former PhD student. Axel is still working on AMT, but because I want him to be as independent as possible, I refrain from collaborating with him on this topic. Since 2023, we have started to collaborate with Christophe Kervazo and Mathieu Fontaine (Telecom Paris) on unrolled NMF for AMT. We are currently seeking motivated PhD candidates and funding.